增加故障转移
发布于 2016-02-29 14:36:40 | 491 次阅读 | 评论: 0 | 来源: 网络整理
增加故障转移
在单一节点上运行意味着有单点故障的风险——没有数据备份。幸运的是,要防止单点故障,我们唯一需要做的就是启动另一个节点。
启动第二个节点
为了测试在增加第二个节点后发生了什么,你可以使用与第一个节点相同的方式启动第二个节点(《运行Elasticsearch》一章),而且命令行在同一个目录——一个节点可以启动多个Elasticsearch实例。
只要第二个节点与第一个节点有相同的
cluster.name(请看./config/elasticsearch.yml文件),它就能自动发现并加入第一个节点所在的集群。如果没有,检查日志找出哪里出了问题。这可能是网络广播被禁用,或者防火墙阻止了节点通信。
如果我们启动了第二个节点,这个集群看起来就像下图。
双节点集群——所有的主分片和复制分片都已分配:
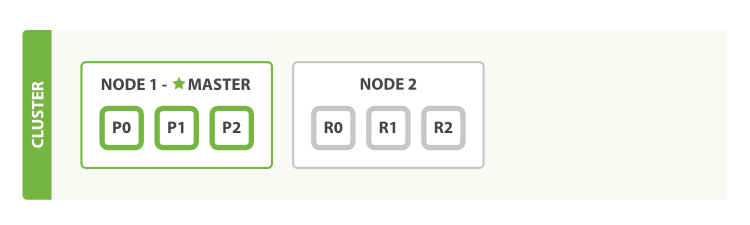
第二个节点已经加入集群,三个复制分片(replica shards)也已经被分配了——分别对应三个主分片,这意味着在丢失任意一个节点的情况下依旧可以保证数据的完整性。
文档的索引将首先被存储在主分片中,然后并发复制到对应的复制节点上。这可以确保我们的数据在主节点和复制节点上都可以被检索。
cluster-health现在的状态是green,这意味着所有的6个分片(三个主分片和三个复制分片)都已可用:
{
"cluster_name": "elasticsearch",
"status": "green", <1>
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}- 集群的状态是`green`.
我们的集群不仅是功能完备的,而且是高可用的。