应对故障
发布于 2016-02-29 14:35:09 | 300 次阅读 | 评论: 0 | 来源: 网络整理
应对故障
我们已经说过Elasticsearch可以应对节点失效,所以让我们继续尝试。如果我们杀掉第一个节点的进程(以下简称杀掉节点),我们的集群看起来就像这样:
图5:杀掉第一个节点后的集群
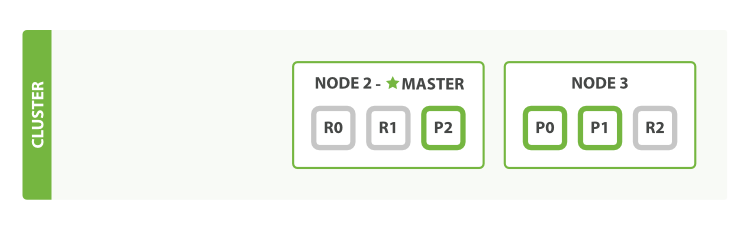
我们杀掉的节点是一个主节点。一个集群必须要有一个主节点才能使其功能正常,所以集群做的第一件事就是各节点选举了一个新的主节点:Node 2。
主分片1和2在我们杀掉Node 1时已经丢失,我们的索引在丢失主分片时不能正常工作。如果此时我们检查集群健康,我们将看到状态red:不是所有主节点都可用!
幸运的是丢失的两个主分片的完整拷贝存在于其他节点上,所以新主节点做的第一件事是把这些在Node 2和Node 3上的复制分片升级为主分片,这时集群健康回到yellow状态。这个提升是瞬间完成的,就好像按了一下开关。
为什么集群健康状态是yellow而不是green?我们有三个主分片,但是我们指定了每个主分片对应两个复制分片,当前却只有一个复制分片被分配,这就是集群状态无法达到green的原因,不过不用太担心这个:当我们杀掉Node 2,我们的程序依然可以在没有丢失数据的情况下继续运行,因为Node 3还有每个分片的拷贝。
如果我们重启Node 1,集群将能够重新分配丢失的复制分片,集群状况与上一节的 图5:增加number_of_replicas到2 类似。如果Node 1依旧有旧分片的拷贝,它将会尝试再利用它们,它只会从主分片上复制在故障期间有数据变更的那一部分。
现在你应该对分片如何使Elasticsearch可以水平扩展并保证数据安全有了一个清晰的认识。接下来我们将会讨论分片生命周期的更多细节。