SequoiaDB 巨杉数据库
![]()
SequoiaDB(巨杉数据库)是一款分布式非关系型文档数据库,可以被用来存取海量非关系型的数据,其底层主要基于分布式,高可用,高性能与动态数据类型设计Sequoiadb可以独立作为一款高性能可扩展的Nosql数据库使用,也可与当前主流分布式计算框架Hadoop紧密集成。
SequoiaDB数据库,提供了基于PC服务器的大规模集群数据平台,为IT部门在提供稳定,可靠以及高效数据服务的同时,大大降低IT部门应用程序的开发,部署以及维护成本。
SequoiaDB数据库的主要特点:
1)通过非结构化存储与分布式处理,提供了近线性的水平扩张能力,让底层的存储不再成为瓶颈。
2)提供了完善的企业级功能,让用户轻松管理高并发性任务,以及海量数据分析。
3)增强的非关系型数据模型,帮助企业快速开发和部署应用程序,做到应用程序的随需应变。
4)提供了最终一致性与强一致性的双重机制,从根本上杜绝数据缺失。
5)提供了在线应用与大数据分析的后台数据库的结合,通过读写分离机制做到同系统中数据分析与在线业务互不干扰。
6)提供了精确到分区级别的高可用性,预防服务器,机房故障以及人为错误,让数据24x7永远在线。
功能特性:
2)SequoiaDB命令行是一个交互式的JavaScript执行环境,几乎所有SequoiaDB支持的命令都通过命令行执行
3)SequoiaDB提供了与PostgreSQL关系型数据库连接的外部表驱动,使用户可以通过标准SQL访问SequoiaDB。
4)SequoiaDB支持很多类型的查询。包括了键值对查询、范围查询和聚合框架查询。此外,SequoiaDB还配备了查询优化器,自动优化查询。
5)SequoiaDB包括文档中任何字段多种类型的索引,包括唯一索引、复合索引以数组索引。
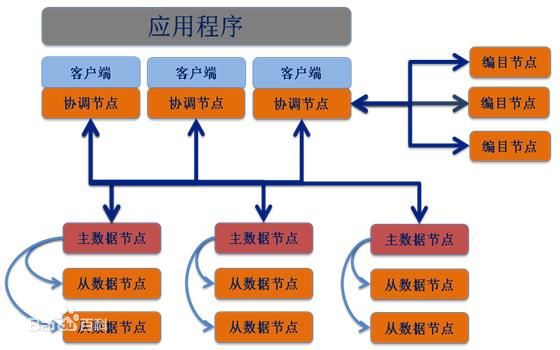
系统基本架构
- SequoiaDB 关于 MongoDB 安全事件的一些思考
-
刚刚过去的这个周末,各位大数据和数据库从业者想必是被MongoDB的“安全事件”给刷屏了,MongoDB作为当前NoSQL在全球的领军人物,遭到这么大规模的黑客攻击,这也再次让我们对于新一代的开源数据库的数据安全问题带来了思考。而 SequoiaDB 巨杉数据库作为国内领先的新一代分布式数据库厂商,我们也来说说我们对这个事
发布于 2017-01-09 09:19:06 | 193 次阅读
- 巨杉斩获“中国十大开源软件”,开源与企业级结合商业路线得到认可
-
随着开源软件在行业中的地位不断深入,越来越多的企业开始将开源软件、分布式计算等新技术提升到了企业IT的战略层面。那么开源软件未来的发展趋势如何?整体行业如何保持旺盛的生命力与创新?这些都是很多
发布于 2016-12-07 02:38:47 | 121 次阅读
- SequoiaDB 连续2年入选红鲱鱼全球创新100强
-
11月15-17日,2016年《红鲱鱼》全球100强名单揭晓,SequoiaDB 巨杉数据库继在去年11月获得了全球创新大奖100强后,再次斩获全球100强的殊荣。这也是硅谷大数据领域对 SequoiaDB 技术创新的肯定。SequoiaDB
发布于 2016-11-24 23:52:03 | 86 次阅读
- 开源数据库 SequoiaDB 获 1000 万美元融资
-
SequoiaDB 数据库源码:http://git.oschina.net/wangzhonnew/SequoiaDB国内领先的新一代分布式数据库厂商SequoiaDB巨杉数据库,宣布获得世界顶级投资机构DCM领投的B轮融资1000万美元,A轮投资机构启明创投跟投。在当前的资本寒冬之下,巨杉此次B轮融资,体现了投资界对于这家务实的大数据基础软件公司发展的一致看好,而此
发布于 2016-07-14 02:27:26 | 174 次阅读
最新资讯
月排行榜