Heritrix web爬虫
![]()
Heritrix是一个开源,可扩展的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格按照robots.txt文件的排除指示和META robots标签。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix是一个爬虫框架,其组织结构如图2.1所示,包含了整个组件和抓取流程:
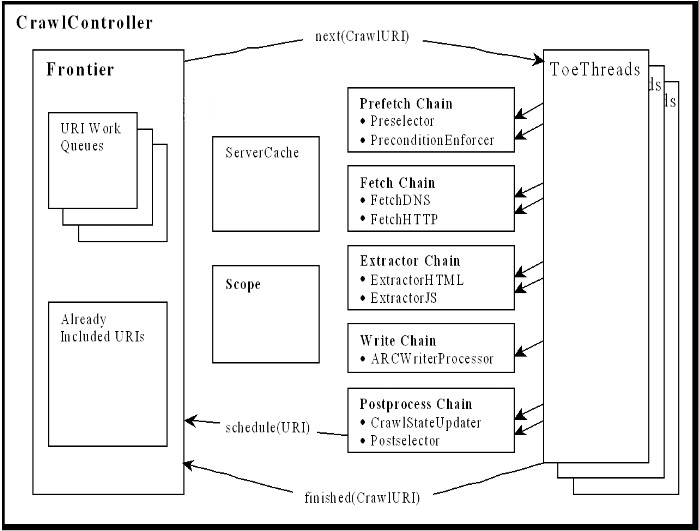
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。控制器结构图如图2.2所示:
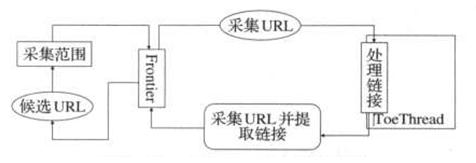
图2.2 CrawlController类结构图
CrawlController类是整个爬虫的总控制者,控制整个抓取工作的起点,决定整个抓取任务的开始和结束。CrawlController从FrontIEr获取URL,传递给线程池(ToePool)中的ToeThread处理。
Frontier(边界控制器)主要确定下一个将被处理的URL,负责访问的均衡处理,避免对某一Web服务器造成太大的压力。Frontier保存着爬虫的状态,包括已经找到的URI、正在处理中的URI和已经处理过的URI。
Heritrix是按多线程方式抓取的爬虫,主线程把任务分配给Teo线程(处理线程),每个Teo线程每次处理一个URL。Teo线程对每个URL执行一遍URL处理器链。URL处理器链包括如下5个处理步骤。整个流程都在图2.1中。
(1)预取链:主要是做一些准备工作,例如,对处理进行延迟和重新处理,否决随后的操作。
(2)提取链:主要是下载网页,进行DNS转换,填写请求和响应表单。
(3)抽取链:当提取完成时,抽取感兴趣的HTML和JavaScript,通常那里有新的要抓取的URL。
(4)写链:存储抓取结果,可以在这一步直接做全文索引。Heritrix提供了用ARC格式保存下载结果的ARCWriterProcessor实现。
(5)提交链:做和此URL相关操作的最后处理。检查哪些新提取出的URL在抓取范围内,然后把这些URL提交给Frontier。另外还会更新DNS缓存信息。
服务器缓存(Server cache)存放服务器的持久信息,能够被爬行部件随时查到,包括被抓取的Web服务器信息,例如DNS查询结果,也就是IP地址。
- Windows配置heritrix3做网络爬虫开发实例
-
本篇内容主要为大家讲解的是Windows配置heritrix3做网络爬虫开发实例。感兴趣的同学可以参考学习下,具体内容如下:
发布于 2016-07-02 01:57:02 | 135 次阅读