Apache Drill 1.9.0 发布,大型数据集分析系统
发布于 2016-12-01 00:21:26 | 157 次阅读 | 评论: 0 | 来源: 网友投递
Apache Drill
Apache Drill是为大数据集的互动分析而生,是Google的Dremel的开源版本。它的目标是可以高效地对大数据集进行分析,可以运行在1000台以上的服务器,在几秒内处理PB级的数据和万亿条的数据记录,目前Drill还在Apache进行孵化。
Apache Drill 1.9.0 发布了。主要更新如下:
新特性:
-
Asynchronous Parquet reader
-
Parquet filter pushdown
-
Dynamic UDF support
-
HTTPD format plugin
改进:
-
[DRILL-1950] - Implement filter pushdown for Parquet
-
[DRILL-3178] - csv reader should allow newlines inside quotes
-
[DRILL-4309] - Make this option store.hive.optimize_scan_with_native_readers=true default
-
[DRILL-4653] - Malformed JSON should not stop the entire query from progressing
-
[DRILL-4674] - Allow casting to boolean the same literals as in Postgre
-
[DRILL-4752] - Remove submit_plan script from Drill distribution
-
[DRILL-4771] - Drill should avoid doing the same join twice if count(distinct) exists
-
[DRILL-4792] - Include session options used for a query as part of the profile
-
[DRILL-4800] - Improve parquet reader performance
-
[DRILL-4864] - Add ANSI format for date/time functions
-
[DRILL-4865] - Add ANSI format for date/time functions
-
[DRILL-4927] - Add support for Null Equality Joins
-
[DRILL-4967] - Adding template_name to source code generated using freemarker template
-
[DRILL-4986] - Allow users to customize the Drill log file name
-
[DRILL-4987] - Use ImpersonationUtil in RemoteFunctionRegistry
下载地址:
为了帮助企业用户寻找更为有效、加快Hadoop数据查询的方法,Apache 软件基金会发起了一项名为“Drill”的开源项目。Apache Drill 实现了 Google's Dremel.
该项目将会创建出开源版本的谷歌Dremel Hadoop工具(谷歌使用该工具来为Hadoop数据分析工具的互联网应用提速)。而“Drill”将有助于Hadoop用户实现更快查询海量数据集的目的。
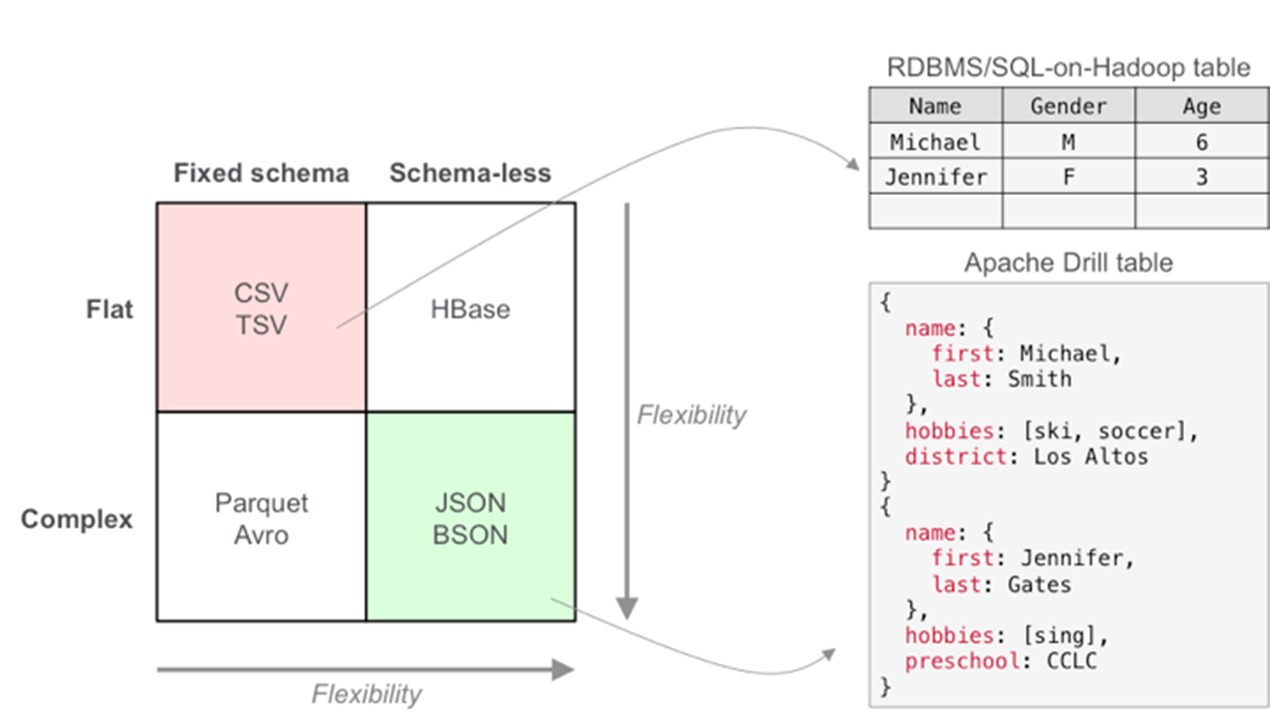
数据结构:
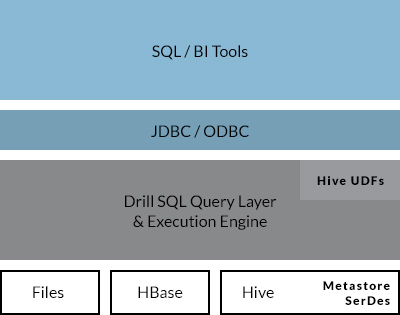
兼容已有的 SQL 环境和 Apache Hive:
历史版本 :
Apache Drill 1.9.0 发布,大型数据集分析系统
Apache Drill 1.0 发布,大型数据集分析系统
Apache Drill 0.4.0 发布,大型数据集分析系统