Spark 2.0 预览:更简单,更快,更智能
发布于 2016-05-12 02:32:34 | 317 次阅读 | 评论: 0 | 来源: 网友投递
Apache Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Apache Spark 2.0 技术预览在 Databricks Community Edition 发布。该预览包使用upstream branch-2.0构建,当启动Cluster时,使用预览包和选择“2.0 (Tech Preview)” 一样简单。

离最终的Apache Spark 2.0发布还有几个星期,现在先来看看有什么新特性:

更简单:SQL和简化的API
Spark 2.0依然拥有标准的SQL支持和统一的DataFrame/Dataset API。但我们扩展了Spark的SQL 性能,引进了一个新的ANSI SQL解析器并支持子查询。Spark 2.0可以运行所有的99 TPC-DS的查询,这需要很多的SQL:2003功能。
在编程API方面,我们已经简化了API:
-
统一Scala/Java下的DataFrames 和 Datasets
-
SparkSession
-
更简单、更高性能的Accumulator API
-
基于DataFrame的Machine Learning API 将成为主要的ML API
-
Machine Learning 管道持久性
-
R中的分布式算法
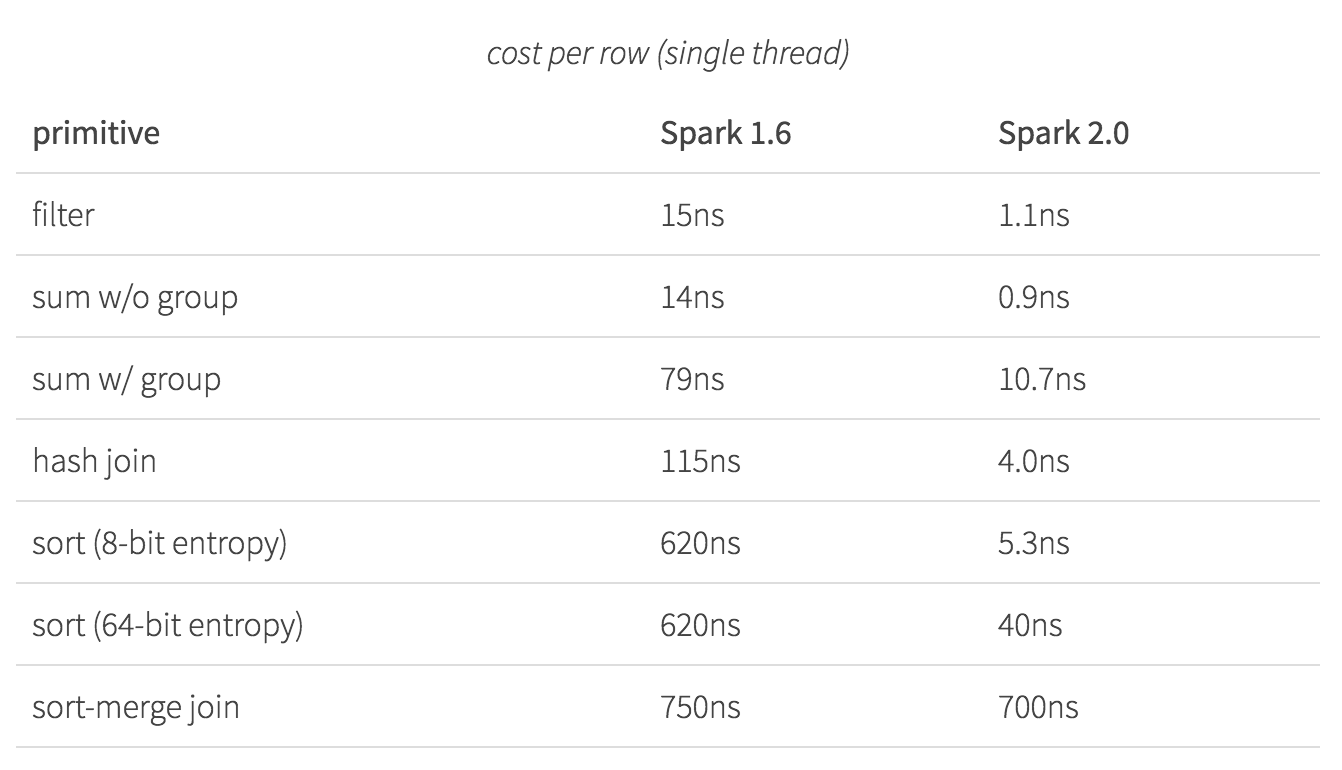
更快:Spark 作为一个编译器
Spark 2.0将拥有更快的速度,下图是Spark 2.0和Spark 1.6的速度对比图:
更智能:结构化数据流
通过在DataFrames之上构建持久化的应用程序来不断简化数据流,允许我们统一数据流,支持交互和批量查询。
了解更多: Spark 2.0: Easier, Faster, and Smarter
历史版本 :
Apache Spark 2.2.0 正式发布,提高可用性和稳定性
Spark 2.0 时代全面到来 —— 2.0.1 版本发布
Apache Spark 2.0.0 发布,APIs 更新
Apache Spark 1.6.2 发布,集群计算环境
Spark 2.0 预览:更简单,更快,更智能
Spark 2.7.6 发布,开源集群计算环境
Apache spark 1.6.1 发布,集群计算环境
Apache Spark 2.0 最快今年4月亮相
Apache Spark 1.6 正式发布,性能大幅度提升
Apache Spark 1.6 预览版:更简便的搜索
Apache Spark 1.5.2 发布,开源集群计算环境
Apache Spark 1.5.1 发布,开源集群计算环境