Hadoop环境安装设置
发布于 2015-07-14 13:50:52 | 798 次阅读 | 评论: 1 | 来源: 网络整理
Hadoop由GNU/Linux平台支持(建议)。因此,需要安装一个Linux操作系统并设置Hadoop环境。如果有Linux操作系统等,可以把它安装在VirtualBox(要具备在 VirtualBox内安装Linux经验,没有装过也可以学习试着来)。
安装前设置
在安装Hadoop之前,需要进入Linux环境下,连接Linux使用SSH(安全Shell)。按照下面提供的步骤设立Linux环境。
创建一个用
在开始时,建议创建一个单独的用户Hadoop以从Unix文件系统隔离Hadoop文件系统。按照下面给出的步骤来创建用户:
- 使用 “su” 命令开启root .
- 创建用户从root帐户使用命令 “useradd username”.
- 现在,可以使用命令打开一个现有的用户帐户“su username”.
打开Linux终端,输入以下命令来创建一个用户。
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwd
SSH设置和密钥生成
SSH设置需要在集群上做不同的操作,如启动,停止,分布式守护shell操作。认证不同的Hadoop用户,需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
下面的命令用于生成使用SSH键值对。复制公钥形成 id_rsa.pub 到authorized_keys 文件中,并提供拥有者具有authorized_keys文件的读写权限。
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
安装Java
Java是Hadoop的主要先决条件。首先,应该使用命令“java-version”验证 java 存在在系统中。 Java version 命令的语法如下。
$ java -version
如果一切顺利,它会给下面的输出。
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果Java还未安装在系统中,那么按照下面的给出的步骤来安装Java。
第1步
下载Java(JDK<最新版> - X64.tar.gz)通过访问以下链接 http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads1880260.html.
然后JDK-7u71-linux-x64.tar.gz将被下载到系统。
第2步
一般来说,在下载文件夹中的Java文件。使用下面的命令提取 jdk-7u71-linux-x64.gz文件。
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gz
第3步
为了使Java提供给所有用户,将它移动到目录 “/usr/local/”。打开根目录,键入以下命令。
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit
第4步
用于设置PATH和JAVA_HOME变量,添加以下命令到~/.bashrc文件。
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/bin
现在从终端验证 java -version 命令如上述说明。
下载Hadoop
下载来自Apache基金会软件,使用下面的命令提取 Hadoop2.4.1。
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exit
Hadoop操作模式
下载 Hadoop 以后,可以操作Hadoop集群以以下三个支持模式之一:
-
本地/独立模式:下载Hadoop在系统中,默认情况下之后,它会被配置在一个独立的模式,用于运行Java程序。
-
模拟分布式模式:这是在单台机器的分布式模拟。Hadoop守护每个进程,如 hdfs, yarn, MapReduce 等,都将作为一个独立的java程序运行。这种模式对开发非常有用。
-
完全分布式模式:这种模式是完全分布式的最小两台或多台计算机的集群。我们使用这种模式在未来的章节中。
在单机模式下安装Hadoop
在这里,将讨论 Hadoop2.4.1在独立模式下安装。
有单个JVM运行任何守护进程一切都运行。独立模式适合于开发期间运行MapReduce程序,因为它很容易进行测试和调试。
设置Hadoop
可以通过附加下面的命令到 ~/.bashrc 文件中设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop
在进一步讨论之前,需要确保Hadoop工作正常。发出以下命令:
$ hadoop version
如果设置的一切正常,那么应该看到以下结果:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4
这意味着Hadoop在独立模式下工作正常。默认情况下,Hadoop被配置为在非分布式模式的单个机器上运行。
示例
让我们来看看Hadoop的一个简单例子。 Hadoop安装提供了下列示例 MapReduce jar 文件,它提供了MapReduce的基本功能,并且可以用于计算,像PI值,字计数在文件等等
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
有 一个输入目录将推送几个文件,要求计算那些文件的单词总数。要计算单词总数,并不需要写MapReduce,提供的.jar文件包含了实现字数。可以尝试 其他的例子使用相同的.jar文件; 发出以下命令通过Hadoop hadoop-mapreduce-examples-2.2.0.jar 文件检查支持MapReduce功能的程序。
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar
第1步
创建输入临时目录的内容文件。可以在任何地方创建此输入目录用来工作。
$ mkdir input
$ cp $HADOOP_HOME/*.txt input
$ ls -l input
它会在输入目录中的给出以下文件:
total 24
-rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt
这些文件已从Hadoop安装主目录被复制。为了实验,可以有不同大型的文件集。
第1步
让我们启动Hadoop进程计数在所有在输入目录中可用的文件的单词总数,具体如下:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input ouput
第3步
步骤2 将做必要的处理并保存输出在output/part-r00000文件中,可以通过查询使用:
$cat output/*
它会列出了所有的单词以及它们在所有输入目录中的文件提供总计数。
"AS 4
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE” 1
"Not 1
"Object" 1
"Source” 1
"Work” 1
"You" 1
"Your") 1
"[]" 1
"control" 1
"printed 1
"submitted" 1
(50%) 1
(BIS), 1
(C) 1
(Don't) 1
(ECCN) 1
(INCLUDING 2
(INCLUDING, 2
.............
模拟分布式模式安装Hadoop
按照下面给出的在伪分布式模式下安装Hadoop2.4.1的步骤。
第1步:设置Hadoop
可以通过附加下面的命令到~/.bashrc文件中设置Hadoop环境变量。
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
现在,提交所有更改到当前正在运行的系统。
$ source ~/.bashrc
第2步:Hadoop配置
可以找到位置“$HADOOP_HOME/etc/hadoop”下找到所有Hadoop配置文件。这是需要根据Hadoop基础架构进行更改这些配置文件。
$ cd $HADOOP_HOME/etc/hadoop
为了使用Java开发Hadoop程序,必须用java在系统中的位置替换JAVA_HOME值并重新设置hadoop-env.sh文件的java环境变量。
export JAVA_HOME=/usr/local/jdk1.7.0_71
以下是必须编辑配置Hadoop的文件列表。
core-site.xml
core-site.xml文件中包含如读/写缓冲器用于Hadoop的实例的端口号的信息,分配给文件系统存储,用于存储所述数据存储器的限制和大小。
打开core-site.xml 并在<configuration>,</configuration>标记之间添加以下属性。
<configuration>
<property>
<name>fs.default.name </name>
<value> hdfs://localhost:9000 </value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 文件中包含如复制数据的值,NameNode路径的信息,,本地文件系统的数据节点的路径。这意味着是存储Hadoop基础工具的地方。
让我们假设以下数据。
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开这个文件,并在这个文件中的<configuration></configuration>标签之间添加以下属性。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
注:在上面的文件,所有的属性值是用户定义的,可以根据自己的Hadoop基础架构进行更改。
yarn-site.xml
此文件用于配置成yarn在Hadoop中。打开 yarn-site.xml文件,并在文件中的<configuration></configuration>标签之间添加以下属性。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此文件用于指定正在使用MapReduce框架。缺省情况下,包含Hadoop的模板yarn-site.xml。首先,它需要从mapred-site.xml复制。获得mapred-site.xml模板文件使用以下命令。
$ cp mapred-site.xml.template mapred-site.xml
打开mapred-site.xml文件,并在此文件中的<configuration></configuration>标签之间添加以下属性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证Hadoop安装
下面的步骤用来验证Hadoop安装。
第1步:名称节点设置
使用命令“hdfs namenode -format”如下设置名称节点。
$ cd ~
$ hdfs namenode -format
预期的结果如下
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/
第2步:验证Hadoop的DFS
下面的命令用来启动DFS。执行这个命令将启动Hadoop文件系统。
$ start-dfs.sh
期望的输出如下所示:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
第3步:验证Yarn 脚本
下面的命令用来启动yarn脚本。执行此命令将启动yarn守护进程。
$ start-yarn.sh
预期输出如下:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
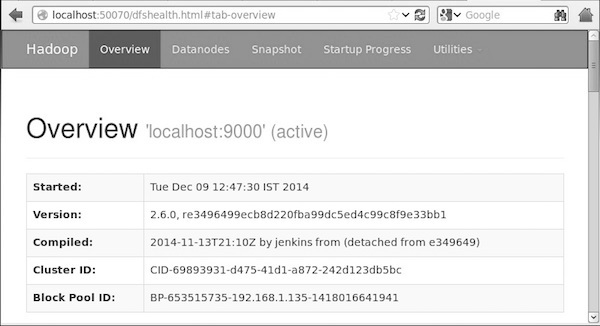
第4步:在浏览器访问Hadoop
访问Hadoop默认端口号为50070,使用以下网址获得浏览器Hadoop的服务。
http://localhost:50070/
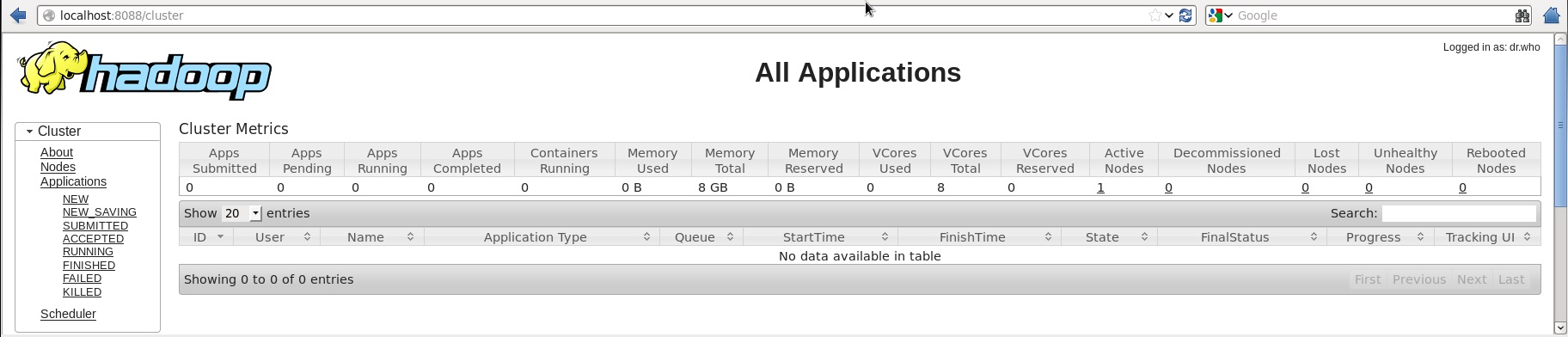
第5步:验证所有应用程序的集群
访问集群中的所有应用程序的默认端口号为8088。使用以下URL访问该服务。
http://localhost:8088/