Cassandra 3.0 的新特性介绍: 物化视图
发布于 2015-07-02 00:49:52 | 336 次阅读 | 评论: 0 | 来源: 网友投递
Apache Cassandra 开源分布式Key-Value存储系统
Apache Cassandra是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于储存特别大的数据。Facebook目前在使用此系统。
Cassandra 数据模型的基本规则 涉及到一些基于运行于列表中的查询的手动非规范化数据。目前,不通过特定分区键来查询栏的唯一方法是使用二级指标, 但是它们不能代替新表数据的非规范性,就像它们不适合高基数数据。高基数二级指标查询通常需要环中各个节点的响应,这样就会增加每个请求的延迟。相反,客 户端的非规范化和多独立表的使用,意味着同样的代码可以为不同的用户重写。在 3.0 版本中,Cassandra 将引入新的特性 —— 物化视图。物化视图可以处理自动化服务端的非规范化,移除客户端处理非规范化的需求,并且能确保基库(base)和视图数据的最终一致性。这个非规范化允许每个视图数据的超快速查询使用正常的 Cassandra 读取路径。
一个例子
作为一个物化视图如何使用的例子,假设我们跟踪了几个游戏的高分玩家。我们有几个需要得到回答的疑问:
-
给定一个游戏,谁的分数会最高?分数是多少?
-
给定一个游戏和一天时间,谁的分数会最高?分数是多少?
-
给定一个游戏和一个月时间,谁的分数会最高?分数是多少?
物 化视图保证了每个 CQL 行对应的基库和视图,所以我们需要确保视图需要的每个 CQL 行会反映在基础列表的主键上。对于第一个查询,我们需要这个游戏、玩家、和他们最高的分数。对于第二个查询,我们需要游戏、玩家、他们最高分数,还有一 天、一个月、一年的最高分数。对于最终的查询,我们需要第二个查询除了天数之外的所有数据。第二个查询的数据是最严格的,所以它决定了我们使用的主键。用 户可以在某天刷新他们的高分,所以我们只要在特定的日期中跟踪最高分就行了。
CREATE TABLE scores ( user TEXT, game TEXT, year INT, month INT, day INT, score INT, PRIMARY KEY (user, game, year, month, day) )
然后,我们会创建一个展示全时间段高分的视图。为了创建物化视图,我们提供了一个简单的选择状态和这个视图所要用到的主键。指定的 CLUSTERING ORDER BY 可以让我们反转高分的排序,这样我们就可以简单地选择每个分区的第一项就能获取最高分数。
CREATE MATERIALIZED VIEW alltimehigh AS SELECT user FROM scores PRIMARY KEY (game, score) WITH CLUSTERING ORDER BY (score desc)
为了查询一天之中的高分,我们创建了一个聚合了游戏标题和数据的物化视图,这样就能让单个分区包含每个日期的值。对于月的最高分,我们也是这么做的。
CREATE MATERIALIZED VIEW dailyhigh AS SELECT user FROM scores PRIMARY KEY ((game, year, month, day), score) WITH CLUSTERING ORDER BY (score DESC) CREATE MATERIALIZED VIEW monthlyhigh AS SELECT user FROM scores PRIMARY KEY ((game, year, month), score) WITH CLUSTERING ORDER BY (score DESC)
我们在物化视图中加入了数据。我们只在分数列表中插入数据,并且 Cassandra 会填充相应的物化视图。
INSERT INTO scores (user, game, year, month, day, score) VALUES ('pcmanus', 'Coup', 2015, 05, 01, 4000)
INSERT INTO scores (user, game, year, month, day, score) VALUES ('jbellis', 'Coup', 2015, 05, 03, 1750)
INSERT INTO scores (user, game, year, month, day, score) VALUES ('yukim', 'Coup', 2015, 05, 03, 2250)
INSERT INTO scores (user, game, year, month, day, score) VALUES ('tjake', 'Coup', 2015, 05, 03, 500)
INSERT INTO scores (user, game, year, month, day, score) VALUES ('jmckenzie', 'Coup', 2015, 06, 01, 2000)
INSERT INTO scores (user, game, year, month, day, score) VALUES ('iamaleksey', 'Coup', 2015, 06, 01, 2500)
INSERT INTO scores (user, game, year, month, day, score) VALUES ('tjake', 'Coup', 2015, 06, 02, 1000)
INSERT INTO scores (user, game, year, month, day, score) VALUES ('pcmanus', 'Coup', 2015, 06, 02, 2000)
现在我们可以查询用户在游戏中获得最高分:
SELECT user, score FROM alltimehigh WHERE game = 'Coup' LIMIT 1
user | score-----------+------- pcmanus | 4000 |
每日最高分:
SELECT user, score FROM dailyhigh WHERE game = 'Coup' AND year = 2015 AND month = 06 AND day = 01 LIMIT 1 |
user | score-----------+-------iamaleksey | 2500 |
所有的项都拷贝到了全时段高分物化视图中:
SELECT user, score FROM alltimehigh WHERE game = 'Coup' |
user | score-----------+------- pcmanus | 4000iamaleksey | 2500 yukim | 2250 jmckenzie | 2000 pcmanus | 2000 jbellis | 1750 tjake | 1000 tjake | 500因为视图中每个 CQL 行都对应着基库中 CQL 行,“pcmanus”和“tjake”在高分列表中出现了多次,同样也在相应日期的基表中出现了多次。
我们也可以从基表中删除行,并且物化视图上的记录也会被删除。我们删除分数列表的 tjake 行:
DELETE FROM scores WHERE user = 'tjake'
现在,查找所有的分数,tjake 项就找不到了。
SELECT user, score FROM alltimehigh WHERE game = 'Coup'user | score-----------+------- pcmanus | 4000iamaleksey | 2500 yukim | 2250 jmckenzie | 2000 pcmanus | 2000 jbellis | 1750当删除事件发生时,物化视图会在基表中查询所有删除掉的值,并且会为每个物化视图行建立墓碑(tombstone),因为在视图中需要建立墓碑的值不会包含在基表的墓碑中。对于独立的基础墓碑,会产生两个视图墓碑;一个用于(tjake, 1000),一个用于(tjake, 500)。
它是怎样工作的?
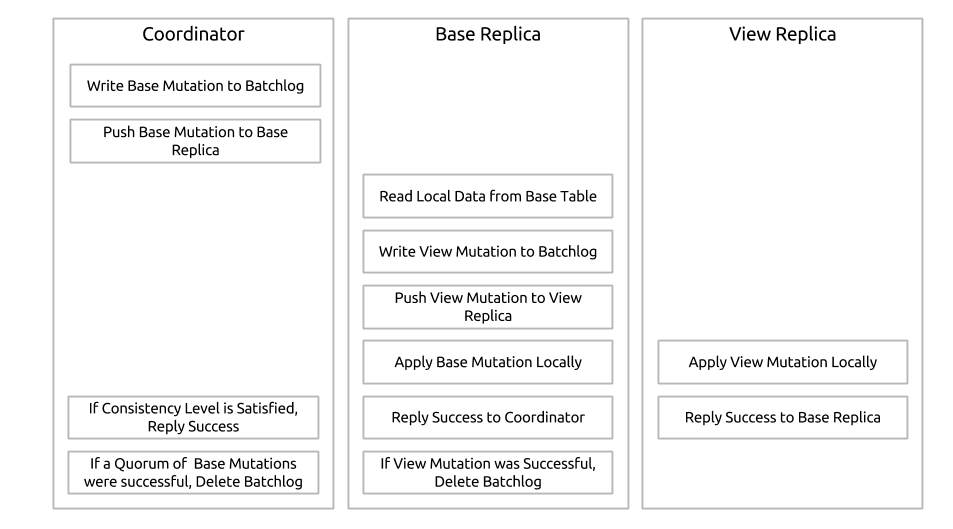
Base Replica 执行本地数据的读取动作是为了建立正确的更新视图。如果视图的主键在基表中被更新,一个墓碑就会被建立,以至于老的值就不会再视图中显示出来。 Batchlog 为基表所提供的数据提供等效额一致性。如果没有 batchlog,视图更新没有应用而基库更新了的话,视图和基库就不会一致。然而,使用 batchlog 会明显增加开销,尤其是因为 batchlog 必须得写入两次。
创建
当物化视图建立而列表中的数据已经存在,一个构建进程就会开始填充物化视图。因此,物化视图可以在现有的列表上建立,但是会有段时间物化视图无法返回所有结果。这个和二级指标的工作方式有点相似。构建完成时,每个节点的 system.built_materializedviews 列表会和视图的名称一起更新。
改变基表
当一个基图被改变,物化视图也会更新。如果物化视图有 SELECT * 语句,任何增加的列会包括在物化视图的列中。任何属于 SELECT 语句而被删除的列会从物化视图中移除。如果基表中的列被改变,同样的改变会发生在视图列表中。如果基表被丢弃,任何相关的视图也会被丢弃。
什么时候不能使用物化视图
-
物化视图没有正常列表所具有的写性能。
物化视图需要额外的读前写(read-before-write)操作,同样,在创建视图更新前要检查每个副本的数据一致性。这些额外的开销可能会改变写操作延迟。
-
如果行在放入视图之前要被组合,物化视图会无法工作。物化视图会创建一个基库 CQL 行对应的视图 CQL 行。
-
低基数数据会在环周围创建热点。
如果所有数据的分区键都是相同的,这些节点就会过载。在
alltimehigh物化视图上,如果我们储存高分的唯一游戏是“Coup”,储存“Coup”的唯一节点就会储存任何数据。 -
目前,只有简单的
SELECT语句被支持,但是已经有提议要增加对更复杂SELECT语句的支持。WHERE条款,ORDER BY,和函数在物化视图中不可用。 -
如果有大量的分区墓碑,那性能就会备受煎熬;物化视图就必须查询现有的全部值,并且为每个值创建一个墓碑。每个基表删除的 CQL 行都会有个物化视图的墓碑。
-
物化视图不支持 Thrift。
历史版本 :
Cassandra 2.2 发布,支持 Windows 系统
Cassandra 3.0 的新特性介绍: 物化视图
Cassandra v2.1 发布,分布式K/V存储系统