Hadoop 2.7.0 发布,不再支持 JDK 6
发布于 2015-04-24 15:02:25 | 231 次阅读 | 评论: 0 | 来源: 网友投递
Hadoop分布式系统
一个分布式系统基础架构,由Apache基金会所开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
Apache Hadoop 2.7.0 发布,包括大量显著改进,值得关注的改进如下:
-
重大改进
-
此版本不再支持 JDK 6 运行时,仅支持 JDK 7+
-
此版本不适用于生产环境!还有一些重要的问题需要通过测试,用于生产环境的用户请等待 2.7.1/2.7.2
-
-
Hadoop Common
-
支持 Windows Azure 存储 —— Blob
-
-
Hadoop HDFS
-
支持文件截断
-
支持每个存储类型配额
-
支持可变长度的文件块
-
-
Hadoop YARN
-
YARN 认证可插拔
-
自动分享,全局缓存 YARN 本地化资源(测试阶段)
-
-
Hadoop MapReduce
-
限制一个作业运行的 Map/Reduce 任务
-
加快大量输出文件时大型作业的 FileOutputCommitter 速度
-
完整改进请看发行说明。
一个分布式系统基础架构,由Apache基金会所开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
Hadoop 是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有 着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
下图是Hadoop的体系结构:
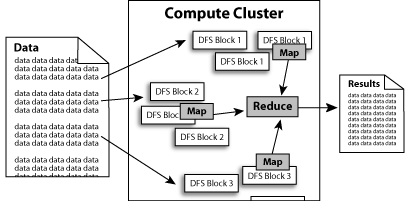
历史版本 :
Apache Hadoop 3.0.0 GA 版正式发布
Apache Hadoop 3.0.0-alpha1,重写 Shell 脚本
Apache Hadoop 2.6.1 发布
Hadoop 2.7.0 发布,不再支持 JDK 6
Spring for Apache Hadoop 2.1.0.M2 发布
Spring for Apache Hadoop 2.0.3 发布
官方正式发布 Apache Hadoop 2.5.0 版本
Hadoop 2.5.0 发布,分布式系统基础架构
Nut 19.2 发布,Lucene+Hadoop 分布式运行框架