SQL Server数据库中伪列及伪列的含义详解
发布于 2018-03-15 01:23:58 | 231 次阅读 | 评论: 0 | 来源: 网友投递
这里有新鲜出炉的SQL Server教程,程序狗速度看过来!
SQL Server 数据库
SQL Server 即 Microsoft SQL Server 。
SQL是英文Structured Query Language的缩写,意思为结构化查询语言。SQL语言的主要功能就是同各种数据库建立联系,进行沟通。按照ANSI(美国国家标准协会)的规定,SQL被作为关系型数据库管理系统的标准语言。
这篇文章主要给大家介绍了关于SQL Server数据库中伪列及伪列含义的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。
SQL Server中的伪列
下午看QQ群有人在讨论(非聚集)索引的存储,说,对于聚集索引表,非聚集索引存储的是索引键值+聚集索引键值;对于非聚集索引表,索引存储的是索引键值+RowId,这应该是一个常识,对此不作具体详细阐述。
这里主要是提到的RowId引起了一点思考。
那么,这个RowId是个什么玩意?能不能更加直观一点来看看RowId的信息?代表什么含义?这个当然也是可以的。
Oracle中的表中有一个伪列的概念,就是在查询表的时候加上select rowid,* from Table,会查询出来伪列。
SQL Server中同样有这么一个伪列,在SQL Server中,这个伪列可以认为是数据行的物理地址,下面简单来观察一下这个RowId以及RowId的含义。
伪列的测试
建一张简单的表,下面借助这个表来查看说明伪列
CREATE TABLE Test
(
id int identity(1,1),
name varchar(50)
)
GO
INSERT INTO Test VALUES (NEWID())
GO 100SQL Server中有一个未公开的伪列“%%physloc%%”,也就是在查询的时候,对于任何一张表,可以加上这个字段,比如如下,就可以查到表中每一行的伪列。
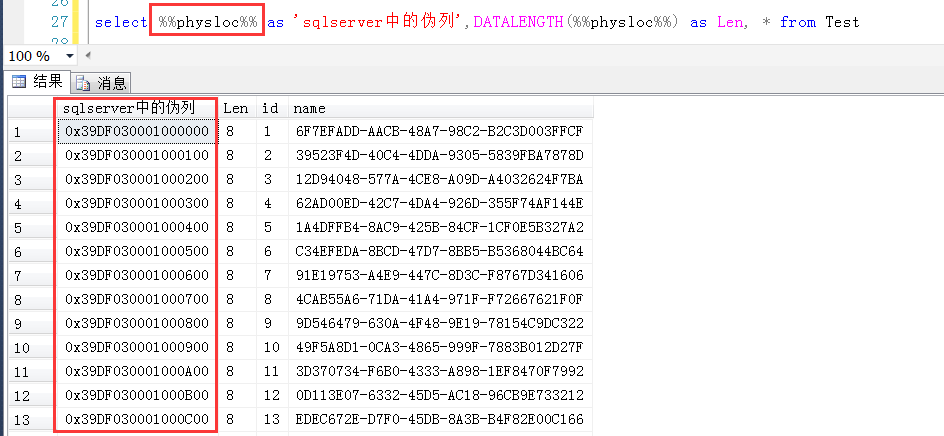
这个伪列的类型是binary(8) ,也就是有8个字节,参考上图的DATALENGTH(%%physloc%%) as Len,%%physloc%%返回的记录的物理地址,其中前四个字节表示页号,中间两个字节表示文件号,最后两个字节表示槽号
为了更加方便地观察伪列的含义,sqlserver提供了一个未公开的系统函数sys.fn_PhysLocFormatter,下面借助sys.fn_PhysLocFormatter这个函数来继续观察这个伪列
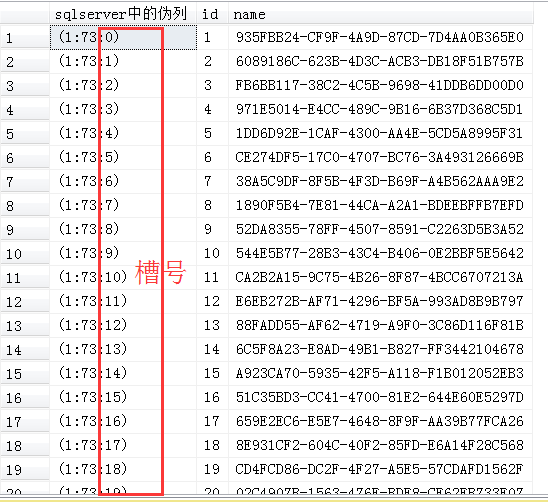
如下图,这里就可以清晰地看到伪列中的信息了。

比如第一行中的(1:73:0),上面说了,其中前四个字节表示页号,中间两个字节表示文件号,最后两个字节表示槽号,(1:73:0)这种格式是经过sys.fn_PhysLocFormatter格式化显式之后的结果。
把文件号1放在最前面,中间的73是页号(page number),最后一位0是槽号(sloc number)。
下面粗略地说一下这几个字段的含义。这里要求对SQL Server的存储只是有一个基本的认识,否则看的云里雾里。
1,首先说什么是文件号
如截图,文件号就是数据库的数据文件编号,这里只有一个数据文件,文件编号为1,建表的时候默认(这里也只能建立)建立在fileid = 1 的文件上面,fileid=2的是日志文件,就不多说了。

2,其次是页号,页号就是分配给当前这张表的数据页面(8kb的最小分配单元)的页号,我们看一下Test这个表的页面情况
借助DBCC IND命令,查询分配给这个表的页面信息,其中77号页面是IMA也面,至于什么事IMA页面,不多解释。
73号页面才是真正存储数据的页,与上面的1:73:0中的73一样,没毛病。

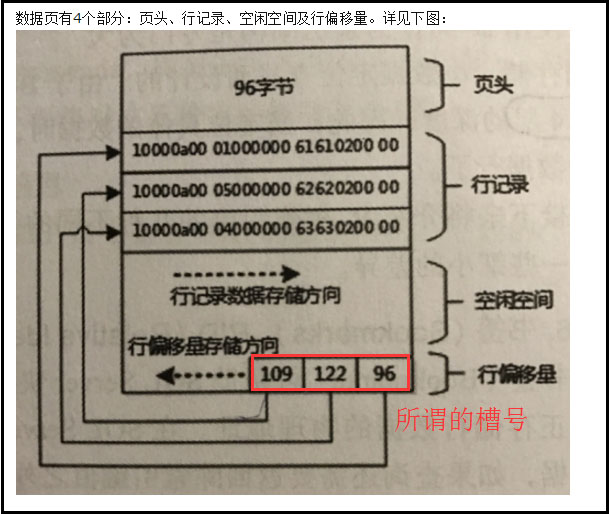
3,最后看一下槽号,槽号的概念要对SQL Server的数据页面有一个基本的认识,这里盗用一张网友的图。
所谓的槽号就是在数据页面中,每个页面存储多行数据,槽号用来标记每一行数据的偏移量,用大白话说就是“存储每一行数据的地址空间开始的位置”,因为每一行数据的总长度是不一样的(存在可变长度列的情况下),每一行的占用的存储空间也是不一样的,槽号或者行偏移量就是说明每一行数据在页内的开始位置。
不过sys.fn_PhysLocFormatter格式化显式的槽号并不是如下截图的偏移量,而是第N个数据行的这个N的信息,因此第1行的槽号就是1,第2行的槽号就是2,以此类推,当第一个page存储满之后,从第二个page开始存储,槽号又从0开始编号且累加
至此,对SQL Server的伪列,也就说经常说的RowId有了一个简单的认识。
这里可以认为,在SQL Server数据库中,伪列RowId就是数据行的物理地址,至于别的数据库中的伪列(RowId)是不是物理地址倒是不确定(很有可能也是的)
这里简单提一下一开始说的一个问题:
为什么SQL Server的聚集表(有聚集索引的表)存储数据的时候存储的是“索引键值+聚集索引键值”,对于非聚集索引表,索引存储的是索引键值+RowId?
或者反过来说,为什么聚集索引表的非聚集索引存储的是“索引键值+聚集索引键值”而不是“索引存储的是索引键值+RowId”
作为一个常识,聚集索引要按照聚集索引的顺序存放,这就意味着聚集索引表的行数据物理位置有可能发生变化,比如在众所周知的“页拆分(page split)”中发生变化,在数据行的物理位置发生了变化的时候,如果非聚集索引存储的是索引键值+RowId,那么这个RowId也势必要发生变化,这个变化当然要耗费一定的性能,为了防止此种情况的发生,聚集表中的非聚集索引存储成相对不变的索引键值+聚集索引键值,因为在数据行的物理位置发生变化的时候,聚集索引键值是相对不变的,这一点也不难理解。
当然有一种例外,当对聚集索引表做更新的时候,直接更新聚集索引的键值,这样的话,也有可能造成聚集索引表中当前数据行的物理位置发生变化,这一点也比较有意思,就不展开叙述了。
这一点跟绕口令一样,这里要求对SQL Server中的聚集索引和非聚集索引,以及存储结构有一个基础的认识才容易理解。
最后高能预警
高能预警,别说我瞎比比误导人,上述解析伪列的函数sys.fn_PhysLocFormatter是一个未公开的函数,未公开的函数就有可能潜在一些问题,事实上这个函数有一个非常严重的bug。
该bug就是在解析物理存储位置的时候有一定的逻辑错误,这个问题早有细心的人分析过了
参考:/article/17/1108/352239.html
目前测试来看,在SQL Server 2014中仍然存在bug,N前年啃书的时候就了解到有这么一个函数,但是一直不想提及sys.fn_PhysLocFormatter这个函数的原因,因此对于未公开的函数,请不要做验证性测试,再次声明:该函数有bug,请谨慎使用。
附上这个函数的源代码,并参考原文的结论
create function sys.fn_PhysLocFormatter (@physical_locator binary (8))
returns varchar (128)
as
begin
declare @page_id binary (4)
declare @file_id binary (2)
declare @slot_id binary (2)
-- Page ID is the first four bytes, then 2 bytes of page ID, then 2 bytes of slot
--
select @page_id = convert (binary (4), reverse (substring (@physical_locator, 1, 4)))
select @file_id = convert (binary (2), reverse (substring (@physical_locator, 5, 2)))
select @slot_id = convert (binary (2), reverse (substring (@physical_locator, 7, 2)))
return '(' + cast (cast (@file_id as int) as varchar) + ':'
+ cast (cast (@page_id as int) as varchar) + ':'
+ cast (cast (@slot_id as int) as varchar) + ')'
end问题出在reverse函数上。
reverse函数的作用是字符反转,而不是字节反转,当遇到81-FE之间的字节时,被认为是双字节字符而组合在一起参与反转操作,造成了错误。
总结
本文简单阐述了SQL Server中的伪列,以及伪列的含义,通过伪列对非聚集索引以及数据行的存储结构有一个简单的了解。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对PHPERZ的支持。