Innodb表select查询顺序
发布于 2017-11-01 09:57:13 | 219 次阅读 | 评论: 0 | 来源: 网友投递
InnoDB MySQL数据库存储引擎
InnoDB 是 MySQL 上第一个提供外键约束的数据存储引擎,除了提供事务处理外,InnoDB 还支持行锁,提供和 Oracle 一样的一致性的不加锁读取,能增加并发读的用户数量并提高性能,不会增加锁的数量。InnoDB 的设计目标是处理大容量数据时最大化性能,它的 CPU 利用率是其他所有基于磁盘的关系数据库引擎中最有效率的。
这篇文章主要介绍了Innodb表select查询顺序的相关资料,需要的朋友可以参考下
今天知数堂一个学生反馈说在优化课中老师讲Innodb是以主键排序存储,读取的时间以主键为顺序读取,但发现个例外,如下:
CREATE TABLE zst_t1 (
uid int(10) NOT NULL AUTO_INCREMENT,
id int(11) NOT NULL,
PRIMARY KEY ( uid ),
KEY idx_id ( id )
) ENGINE=InnoDB;'
写入数据:
INSERT INTO zst_t1 VALUES (1,1),(12,1),(22,1),(23,1),(33,1),(2,2),(3,2),(10,2),(11,2),(4,4),(13,4),(14,4);
执行查询:
select * from zst_t1;
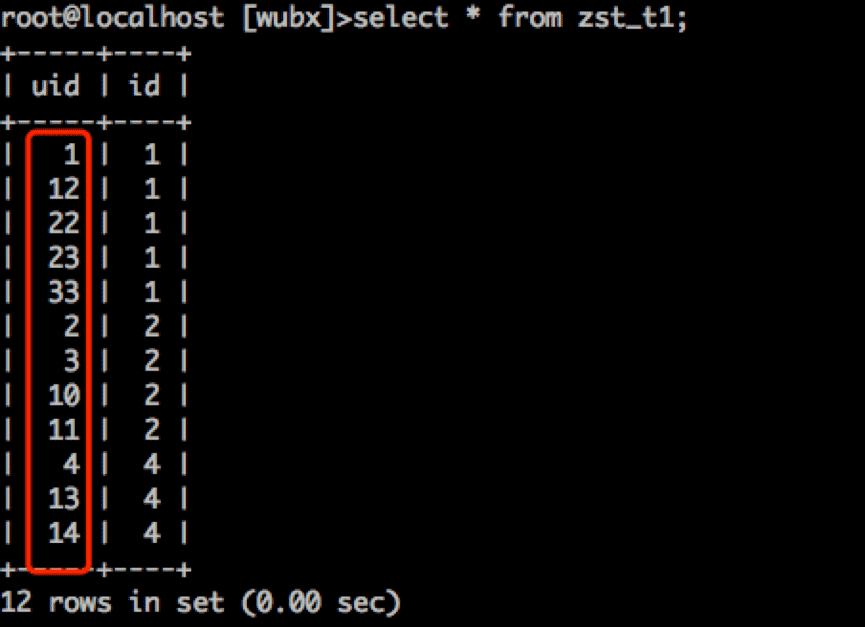
为什么这个顺序是乱的,不按顺序排列呢?难道Innodb表并不是全按主键存储?
使用innodb_ruby这个工具查看一下存储结构什么样
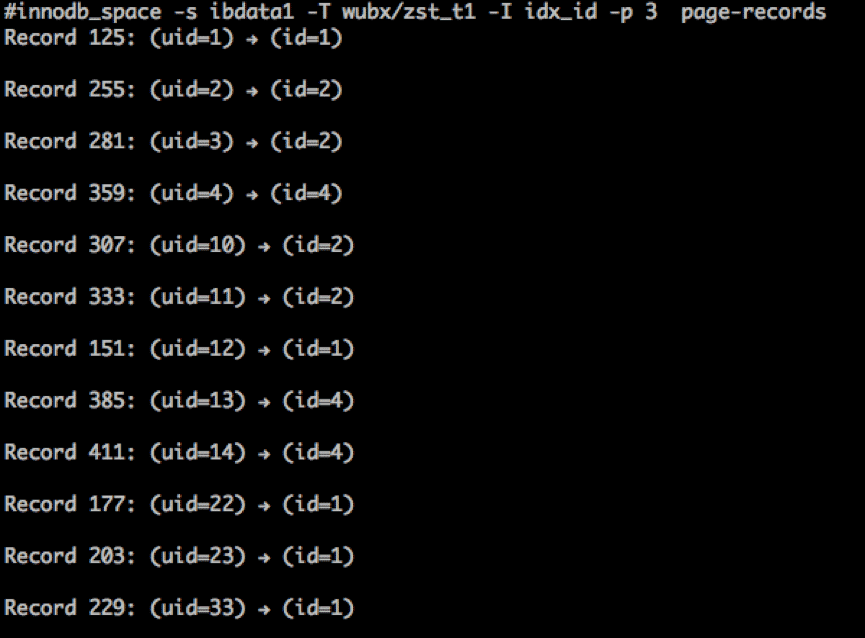
看样子存储还是按主键排序存储的。没毛病。
再来看一下该表的索引:
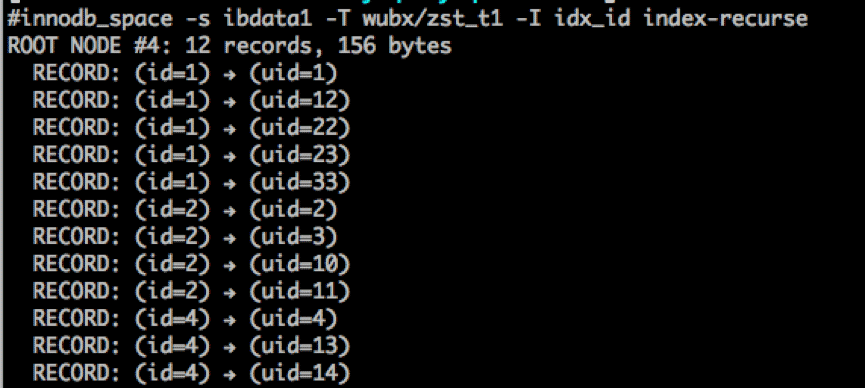
看到这里应该明白了怎么会事了吧,原来这个查询是走的索引覆盖,没有在进行回表读取原数据。另外,也在此说明,Innodb二索索引包含了主键存储。
来继续证明一下:

看到using index 吧,表示这个查询利用索引查询出来结果,不用读取原表。
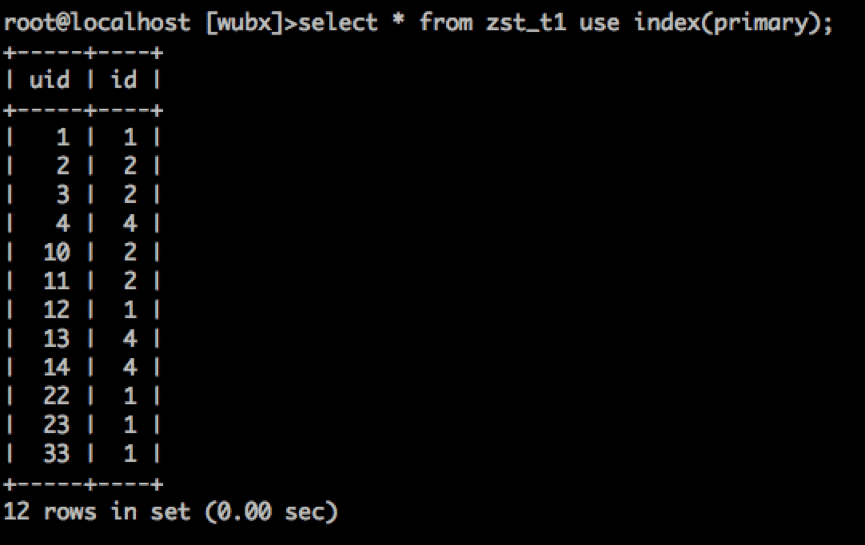
那么我们给造一个通过主键读取数据操作:
select * from zst_t1 use index(primary);

select * from zst_t1 use index(primary); #确认一下。
总结:
这个其实就是一个索引包含的查询案例。 如果静下来思考一下,也许很快就明白了。也不用这样去查问题。
技术在于折腾,多搞搞就明白了:)。
推荐阅读
最新资讯