Elasticsearch 简介
发布于 2017-03-31 01:15:11 | 171 次阅读 | 评论: 0 | 来源: PHPERZ
这里有新鲜出炉的ElasticSearch权威指南,程序狗速度看过来!
ElasticSearch 基于Lucene的搜索引擎
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。支持通过HTTP使用JSON进行数据索引。
我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的。
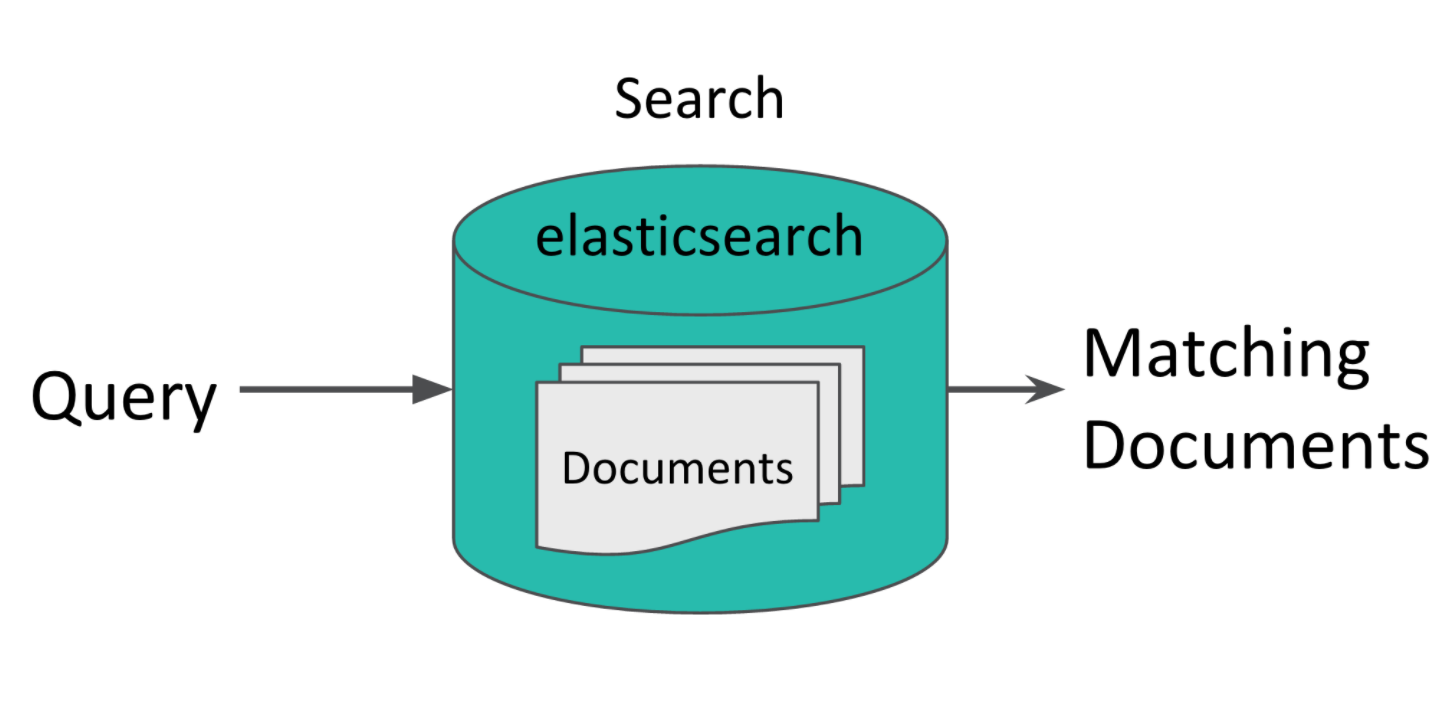
Elasticsearch 是一款稳定高效的分布式搜索和分析引擎,它的底层基于 Lucene,并提供了友好的 RESTful API 来对数据进行操作,还有比较重要的一点是, Elasticsearch 开箱即可用,上手也比较容易。
目前 Elasticsearch 在搭建企业级搜索(如日志搜索、商品搜索等)平台中很广泛,官网也提供了不少案例,比如:
-
GitHub 使用 Elasticsearch 检索超过 800 万的代码库
-
eBay 使用 Elasticsearch 搜索海量的商品数据
-
Netflix 使用 Elasticsearch 来实现高效的消息传递系统
本文主要介绍 Elasticsearch 的基本概念及入门使用。
<!-- more -->
安装
在安装 Elasticsearch 之前,请确保你的计算机已经安装了 Java。目前 Elasticsearch 的最新版是 5.2,需要安装 Java 8,如果你用的是老版本的 Elasticsearch,如 2.x 版,可用 Java 7,但还是推荐使用 Java 8。
可以使用如下的命令检查 Java 的版本:
$ java -version
接着,我们可以从这里下载最新版本的 Elasticsearch,也可使用 wget 下载,如下:
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.tar.gz
Windows 用户也可以下载 .zip 格式的安装包。
下载完后进行解压:
$ tar -zxvf elasticsearch-5.2.2.tar.gz
运行
首先,我们进入到刚刚解压出来的目录中:
$ cd elasticsearch-5.2.2
接着,使用如下命令启动 Elasticsearch:
$ bin/elasticsearch
此时,如果正常的话,你可以在终端看到类似如下的输出:
[2017-03-04T23:25:09,961][INFO ][o.e.n.Node ] [] initializing ...
[2017-03-04T23:25:10,073][INFO ][o.e.e.NodeEnvironment ] [yO11WLM] using [1] data paths, mounts [[/ (/dev/disk0s2)]], net usable_space [141.1gb], net total_space [232.9gb], spins? [unknown], types [hfs]
[2017-03-04T23:25:10,074][INFO ][o.e.e.NodeEnvironment ] [yO11WLM] heap size [1.9gb], compressed ordinary object pointers [true]
[2017-03-04T23:25:10,095][INFO ][o.e.n.Node ] node name [yO11WLM] derived from node ID [yO11WLMOQDuAOpZbYZYjzw]; set [node.name] to override
[2017-03-04T23:25:10,100][INFO ][o.e.n.Node ] version[5.2.2], pid[7607], build[db0d481/2017-02-09T22:05:32.386Z], OS[Mac OS X/10.11.5/x86_64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_102/25.102-b14]
[2017-03-04T23:25:11,363][INFO ][o.e.p.PluginsService ] [yO11WLM] loaded module [aggs-matrix-stats]
...
上面的命令是在前台运行的,如果想在后台以守护进程模式运行,可以加 -d 参数。
Elasticsearch 启动后,也启动了两个端口 9200 和 9300:
-
9200 端口:HTTP RESTful 接口的通讯端口
-
9300 端口:TCP 通讯端口,用于集群间节点通信和与 Java 客户端通信的端口
现在,让我们做一些测试。在浏览器访问链接 http://localhost:9200/ ,或使用 curl 命令:
$ curl 'http://localhost:9200/?pretty'
我们可以看到类似如下的输出:
{
"name" : "yO11WLM",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "yC8BGwzlSnu_zGbKL918Xg",
"version" : {
"number" : "5.2.1",
"build_hash" : "db0d481",
"build_date" : "2017-02-09T22:05:32.386Z",
"build_snapshot" : false,
"lucene_version" : "6.4.1"
},
"tagline" : "You Know, for Search"
}
概念
在进一步使用 Elasticsearch 之前,让我们先了解几个关键概念。
在逻辑层面:
-
Index (索引):这里的 Index 是名词,一个 Index 就像是传统关系数据库的 Database,它是 Elasticsearch 用来存储数据的逻辑区域
-
Document (文档):Elasticsearch 使用 JSON 文档来表示一个对象,就像是关系数据库中一个 Table 中的一行数据
-
Type (类型):文档归属于一种 Type,就像是关系数据库中的一个 Table
-
Field (字段):每个文档包含多个字段,类似关系数据库中一个 Table 的列
我们用一个表格来做类比,如下:
| Elasticsearch | MySQL |
|---|---|
| Index | Database |
| Type | Table |
| Document | Row |
| Field | Column |
在物理层面:
-
Node (节点):node 是一个运行着的 Elasticsearch 实例,一个 node 就是一个单独的 server
-
Cluster (集群):cluster 是多个 node 的集合
-
Shard (分片):数据分片,一个 index 可能会存在于多个 shard
使用
接下来,我们看看如何建立索引、创建文档等,就好比在 MySQL 中进行诸如创建数据库,插入数据等操作。
添加文档
下面,我们将创建一个存储电影信息的 Document:
-
Index 的名称为 movie
-
Type 为 adventure
-
Document 有两个字段:name 和 actors
我们使用 Elasticsearch 提供的 RESTful API 来执行上述操作,如图所示:

-
用 url 表示一个资源,比如
/movie/adventure/1就表示一个index为 movie,type为 adventure,id为 1 的 document -
用 http 方法操作资源,如使用 GET 获取资源,使用 POST、PUT 新增或更新资源,使用 DELETE 删除资源等
我们可以使用 curl 命令来执行上述操作:
$ curl -i -X PUT "localhost:9200/movie/adventure/1" -d '{"name": "Life of Pi", "actors": ["Suraj", "Irrfan"]}'
不过,本文推荐使用 httpie,类似 curl,但比 curl 更好用,将上面的命令换成 httpie,如下:
$ http put :9200/movie/adventure/1 name="Life of Pi" actors:='["Suraj", "Irrfan"]'
上面的命令结果如下:
HTTP/1.1 201 Created
Location: /movie/adventure/1
content-encoding: gzip
content-type: application/json; charset=UTF-8
transfer-encoding: chunked
{
"_id": "1",
"_index": "movie",
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "adventure",
"_version": 1,
"created": true,
"result": "created"
}
可以看到,我们已经成功创建了一个 _index 为 movie,_type 为 adventure,_id 为 1 的文档。
我们通过 GET 请求来查看这个文档的信息:
$ http :9200/movie/adventure/1
结果如下:
HTTP/1.1 200 OK
content-encoding: gzip
content-type: application/json; charset=UTF-8
transfer-encoding: chunked
{
"_id": "1",
"_index": "movie",
"_source": {
"actors": [
"Suraj",
"Irrfan"
],
"name": "Life of Pi"
},
"_type": "adventure",
"_version": 1,
"found": true
}
可以看到,原始的文档数据存在了 _source 字段中。
如果我们的数据没有 id,也可以让 Elasticsearch 自动为我们生成,此时要使用 POST 请求,形式如下:
POST /movie/adventure/
{
"name": "Life of Pi"
}
更新整个文档
当我们使用 PUT 方法指明文档的 _index, _type 和 _id时,如果 _id 已存在,则新文档会替换旧文档,此时文档的 _version 会增加 1,并且 _created 字段为 false。比如:
$ http put :9200/movie/adventure/1 name="Life of Pi"
结果如下:
HTTP/1.1 200 OK
content-encoding: gzip
content-type: application/json; charset=UTF-8
transfer-encoding: chunked
{
"_id": "1",
"_index": "movie",
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "adventure",
"_version": 2,
"created": false,
"result": "updated"
}
使用 GET 请求查看新文档的数据:
$ http :9200/movie/adventure/1
结果如下:
HTTP/1.1 200 OK
content-encoding: gzip
content-type: application/json; charset=UTF-8
transfer-encoding: chunked
{
"_id": "1",
"_index": "movie",
"_source": {
"name": "Life of Pi"
},
"_type": "adventure",
"_version": 2,
"found": true
}
可以看到,actors 这个字段已经不存在了,文档的 _version 变成了 2。
因此,为了避免在误操作的情况下,原文档被替换,我们可以使用 _create 这个 API,表示只在文档不存在的情况下才创建新文档(返回 201 Created),如果文档存在则不做任何操作(返回 409 Conflict),命令如下:
$ http put :9200/movie/adventure/1/_create name="Life of Pi"
由于文档 id 存在,会返回 409 Conflict。
局部更新
在有些情况下,我们只想更新文档的局部,而不是整个文档,这时我们可以使用 _update 这个 API。
现在,待更新的文档信息如下:
{
"_id": "1",
"_index": "movie",
"_source": {
"name": "Life of Pi"
},
"_type": "adventure",
"_version": 2,
"found": true
}
最简单的 update 请求接受一个局部文档参数 doc,它会合并到现有文档中:将对象合并在一起,存在的标量字段被覆盖,新字段被添加。
形式如下:
POST /movie/adventure/1/_update
{
"doc": {
"name": "life of pi"
}
}
由于有嵌套字段,我们可以这样使用 http(这里需要注意使用 POST 方法):
$ echo '{"doc": {"actors": ["Suraj", "Irrfan"]}}' | http post :9200/movie/adventure/1/_update
上面的命令中,我们添加了一个新的字段:actors,结果如下:
HTTP/1.1 200 OK
content-encoding: gzip
content-type: application/json; charset=UTF-8
transfer-encoding: chunked
{
"_id": "1",
"_index": "movie",
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "adventure",
"_version": 3,
"result": "updated"
}
可以看到,_version 增加了 1,result 的结果是 updated。
检索文档
检索某个文档
要检索某个文档很简单,我们只需使用 GET 请求并指出文档的 index, type, id 就可以了,比如:
$ http :9200/movie/adventure/1/
响应内容会包含文档的元信息,文档的原始数据存在 _source 字段中。
我们也可以直接检索出文档的 _source 字段,如下:
$ http :9200/movie/adventure/1/_source
检索所有文档
我们可以使用 _search 这个 API 检索出所有的文档,命令如下:
$ http :9200/movie/adventure/_search
返回结果如下:
{
"_shards": {
"failed": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "1",
"_index": "movie",
"_score": 1.0,
"_source": {
"actors": [
"Suraj",
"Irrfan"
],
"name": "Life of Pi"
},
"_type": "adventure"
}
],
"max_score": 1.0,
"total": 1
},
"timed_out": false,
"took": 299
}
可以看到,hits 这个 object 包含了 hits 数组,total 等字段,其中,hits 数组包含了所有的文档,这里只有一个文档,total 表明了文档的数量,默认情况下会返回前 10 个结果。我们也可以设定 From/Size 参数来获取某一范围的文档,可参考这里,比如:
$ http :9200/movie/adventure/_search?from=1&size=5
当不指定 from 和 size 时,会使用默认值,其中 from 的默认值是 0,size 的默认值是 10。
检索某些字段
有时候,我们只需检索文档的个别字段,这时可以使用 _source 参数,多个字段可以使用逗号分隔,如下所示:
$ http :9200/movie/adventure/1?_source=name
$ http :9200/movie/adventure/1?_source=name,actors
query string 搜索
query string 搜索以 q=field:value 的形式进行查询,比如查询 name 字段含有 life 的电影:
$ http :9200/movie/adventure/_search?q=name:life
DSL 搜索
上面的 query string 搜索比较轻量级,只适用于简单的场合。Elasticsearch 提供了更为强大的 DSL(Domain Specific Language)查询语言,适用于复杂的搜索场景,比如全文搜索。我们可以将上面的 query string 搜索转换为 DSL 搜索,如下:
GET /movie/adventure/_search
{
"query" : {
"match" : {
"name" : "life"
}
}
}
如果使用 httpie,可以这样:
$ echo '{"query": {"match": {"name": "life"}}}' | http get :9200/movie/adventure/_search
如果使用 curl,可以这样:
$ curl -X GET "127.0.0.1:9200/movie/adventure/_search" -d '{"query": {"match": {"name": "life"}}}'
文档是否存在
使用 HEAD 方法查看文档是否存在:
$ http head :9200/movie/adventure/1
如果文档存在则返回 200,否则返回 404。
删除文档
使用 DELETE 方法删除文档:
$ http delete :9200/movie/adventure/1
小结
-
Elasticsearch 通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单
-
在创建文档时,我们可以用 POST 方法指定将文档添加到某个
_index/_type下,来让 Elasticsearch自动生成唯一的_id;而用 PUT 方法指定将文档的_index/_type/_id
本文由 funhacks 发表于个人博客,采用 Creative Commons BY-NC-ND 4.0(自由转载-保持署名-非商用-禁止演绎)协议发布。
非商业转载请注明作者及出处。商业转载请联系作者本人。
本文标题为: Elasticsearch 简介
本文链接为: http://funhacks.net/2017/03/2...