Gitlab 官方对整个数据删除事件的详细说明
发布于 2017-02-02 03:24:07 | 161 次阅读 | 评论: 0 | 来源: 网友投递
GitLab项目管理和代码托管平台
GitLab 是一个用于仓库管理系统的开源项目。使用Git作为代码管理工具,并在此基础上搭建起来的web服务。
昨天,我们(Gitlab)网站的一个数据库发生了严重事故。我们(GitLab.com)丢失了 6 小时的数据库数据(问题,合并请求,用户,评论,片段等)。Git / wiki 存储库和自托管安装不受影响。丢失生产数据是不可接受的。未来几天内,我们将会发布此次事故发生的原因及一系列措施的落实情况。
更新 18:14 UTC:GitLab.com 重新在线
截至撰写本文时,我们正在从 6 小时前的数据库备份中恢复数据。这意味着在 GitLab.com 再次生效的时候,17:20 UTC和 23:25 UTC 之间数据库丢失的任何数据都将恢复。
Git数据(存储库和维基)和 GitLab的自托管实例不受影响。
以下是本次事件的简要摘要,详细内容请查阅文档
事件一:
在 2017/01/31 18:00 UTC ,我们检测到垃圾邮件发送者通过创建片段来攻击数据库,使其不稳定。然后,我们开始了解发生了什么问题进行故障排除,以及如何防范。
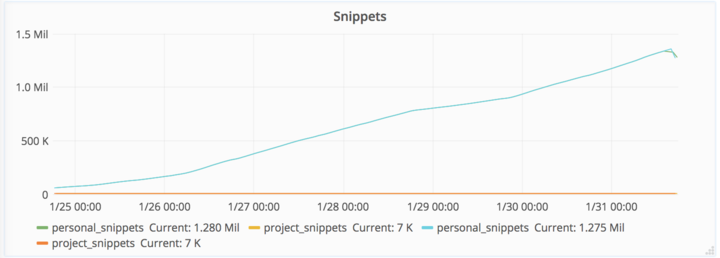
在2017/01/31 21:00 UTC,问题被升级导致在数据库上的写入锁定,这导致网站出现了一些时间段的宕机。

措施:
-
根据IP地址阻止了垃圾邮件发送者
-
删除了使用存储库作为某种形式的CDN 导致 47 000 个IP 使用同一个帐户登录(导致高DB负载)的用户
-
已移除用户发送垃圾邮件(通过创建代码段)
事件二:
在 2017/01/31 22:00 UTC, - 我们被分页,因为 DB 复制滞后太远,导致不能有效地阻止。发生这种情况是因为在辅助数据库没有及时处理写入。
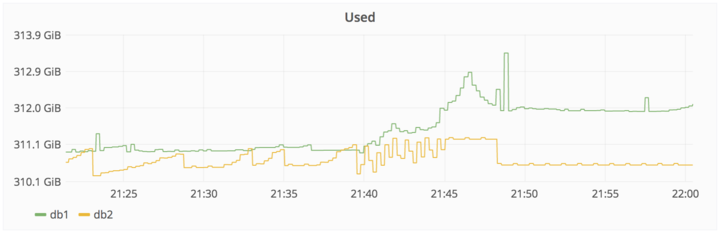
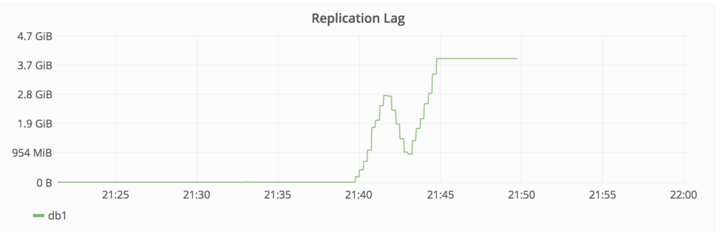
措施:
-
尝试修复 db2,此时丢失数据约4 GB
-
db2.cluster 拒绝复制,/var/opt/gitlab/postgresql/data 擦拭以保证复制
-
db2.cluster 拒绝连接到 db1,max_wal_senders太低。此设置是用来限制数量 WAL (= replication)的客户端
-
团队成员1调整max_wal_senders 到 32上db1,重启 PostgreSQL 。
-
PostgreSQL 因同时打开信号量太多而拒绝重启。
-
团队成员1调整 max_connections 8000 到 2000。PostgreSQL 重启成功(尽管8000已经使用了近一年)
-
db2.cluster 可以链接,但仍然复制失败,只是挂在那里没有执行任何的操作。今晚 23:00 左右(当地时间),团队成员1明确提到他要签字,并未想到会突然出现复制问题。
事件三:
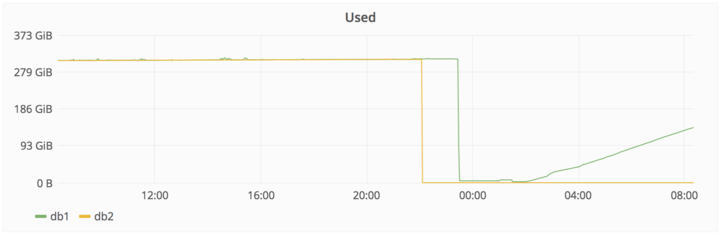
在2017年1月31日23:00 左右 —团队成员1认为, pg_basebackup 拒绝执行是因为 PostgreSQL 的数据目录存在(尽管是空的),于是决定删除该目录。经过一两秒钟,他注意到他运行在 db1.cluster.gitlab.com,而不是 db2.cluster.gitlab.com。
在2017年1月31日23:27 时,团队成员1 -终止删除操作,但为时已晚。大约 300 GB 左右的数据只剩下约4.5 GB
我们不得不把 GitLab.com 下线,并在 Twitter 上公布信息。
-
我们正在执行紧急数据库维护,https://t.co/r11UmmDLDE 将脱机
-
GitLab.com 状态(@gitlabstatus)2017年1月31日
遇到的问题
-
默认情况下,LVM 快照每 24 小时采取一次。为了数据库的工作负载平衡,团队成员 1 在停电前 6小时手动操作过。
-
定期备份似乎也只能每24小时执行一次,虽然团队成员1目前仍未能找出它们的存储位置。团队成员2表示 ,这些似乎没有奏效,产生的文件大小只有几个字节。
-
团队成员3:看起来 pg_dump 可能会失败,因为 PostgreSQL 的 9.2 二进制文件正在运行,而不是 9.6 的二进制文件。这是因为 omnibus 只使用 Pg 9.6 ,如果 data / PG_VERSION 设置为 9.6,但在 workers 上这个文件不存在。因此,它默认为 9.2,静默失败。因此没有做出 SQL 转储。Fog gem 可能已清理旧备份。
-
为Azure 服务器启用 Azure 中的磁盘快照,而不是 DB 服务器。
-
同步过程在 Webhooks 数据同步到暂存后删除。我们只能从过去24小时的定期备份中提取内容,否则将丢失
-
复制过程是超级脆弱,容易出错,依赖少数随机 shell 脚本并记录
-
我们的备份到 S3 显然也不运行:bucket 是空的
-
因此,换句话说,部署的 5 个备份/复制技术中没有一个可靠地运行或设置。我们最终还原了6 小时的备份。
-
pg_basebackup 将等待主机启动复制进程,据另一个生产工程师称,这可能需要 10 分钟。这可能导致进程被卡住。使用 “strace” 运行进程没有提供的有用信息。
恢复
我们正在使用临时数据库中的数据库备份来立即恢复。
我们不小心删除了生产数据,可能必须从备份中还原。谷歌文档与现场笔记 https://t.co/EVRbHzYlk8
GitLab.com 状态(@gitlabstatus)2017年2月1日
-
2017年2月1日00:36 -备份 db1.staging.gitlab.com 数据
-
2017年2月1日00:55 -在 db1.cluster.gitlab.com 安装 db1.staging.gitlab.com
-
从分段复制数据 /var/opt/gitlab/postgresql/data/ 到生成 /var/opt/gitlab/postgresql/data/
-
2017年2月1日01:05 - nfs-share01 服务器 征用临时存储/var/opt/gitlab/db-meltdown
-
2017年2月1日01:18 - 复制剩余的生成数据,包括pg_xlog,升级为20170131-db-meltodwn-backup.tar.gz
下面的图表显示删除的时间和后续的数据复制。
此外,我们要感谢在Twitter 和其他渠道通过#hugops获得的惊人支持
编译自:GitLab.com Database Incident