Torch7 开源 PyTorch:Python 优先深度学习框架
发布于 2017-01-20 04:20:15 | 431 次阅读 | 评论: 0 | 来源: 网友投递
Torch7 科学计算框架
Torch7 是一个科学计算框架,支持机器学习算法。易用而且提供高效的算法实现,得益于 LuaJIT 和一个底层的 C 实现。
Torch7 团队开源了 PyTorch。据官网介绍,PyTorch 是一个 Python 优先的深度学习框架,能够在强大的 GPU 加速基础上实现张量和动态神经网络。
PyTorch 是一个 Python 软件包,其提供了两种高层面的功能:
-
使用强大的 GPU 加速的 Tensor 计算(类似 numpy)
-
构建于基于 tape 的 autograd 系统的深度神经网络
如有需要,你也可以复用你最喜欢的 Python 软件包(如 numpy、scipy 和 Cython)来扩展 PyTorch。目前这个版本是早期的 Beta 版,我们很快就会加入更多的功能。
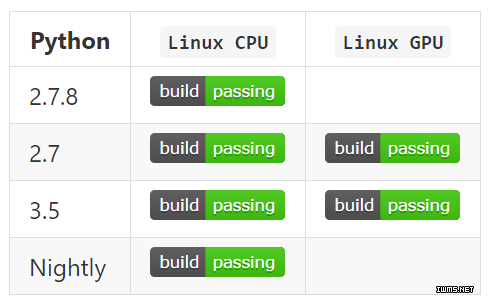
PyTorch 介绍
在粒度层面(granular level)上,PyTorch 库包含了以下组件:

使用 PyTorch 的原因通常有二:
-
作为 numpy 的替代,以便使用强大的 GPU;
-
将其作为一个能提供最大的灵活性和速度的深度学习研究平台。
进一步阐述如下:
一个支持 GPU 的 Tensor 库
如果你使用 numpy,那么你就使用过 Tensor(即 ndarray)。
PyTorch 提供了支持 CPU 和 GPU 的 Tensor,可以极大地加速计算。
我们提供了各种各样的用于加速的张量例程(tensor routine),可以满足你的各种科学计算需求,比如 slicing、索引、数学运算、线性代数、reduction。而且它们非常快!
动态神经网络:基于 tape 的 autograd
PyTorch 有一种独特的神经网络构建方法:使用和重放 tape recorder。TensorFlow、Theano、Caffe 和 CNTK 等大部分框架对世界的视角都是静态的,让人们必须先构建一个神经网络,然后一次又一次地使用同样的结构;如果要想改变该网络的行为,就必须完全从头开始。
但使用 PyTorch,通过一种我们称之为「Reverse-mode auto-differentiation(反向模式自动微分)」的技术,你可以零延迟或零成本地任意改变你的网络的行为。我们灵感来自关于这一主题的许多研究论文以及当前和过去的研究成果,比如 autograd、autograd、Chainer 等。
-
autograd:https://github.com/HIPS/autograd
-
Chainer:http://chainer.org/
尽管这项技术并非 PyTorch 独有,但它仍然是到目前为止最快的实现。你能为你的疯狂研究获得最高的速度和最佳的灵活性。

Python 优先
PyTorch 不是简单地在整体 C++框架上绑定 Python。它深入构建在 Python 之上。你可以像使用 numpy / scipy / scikit-learn 那样轻松地使用 PyTorch。你可以用你喜欢的库和包(如 Cython 和 Numba)在 Python 中编写新的神经网络层。我们的目标是尽量让你不用重新发明轮子。
命令式体验
PyTorch 的设计思路是线性、直观且易于使用。当你需要执行一行代码时,它会忠实执行。PyTorch 没有异步的世界观。当你打开调试器,或接收到错误代码和 stack trace 时,你会发现理解这些信息是非常轻松的。Stack-trace 点将会直接指向代码定义的确切位置。我们不希望你在 debug 时会因为错误的指向或异步和不透明的引擎而浪费时间。
快速精益
PyTorch 具有轻巧的框架。我们集成了各种加速库,如 Intel MKL、英伟达的 CuDNN 和 NCCL 来优化速度。在其核心,它的 CPU 和 GPU Tensor 与神经网络后端(TH、THC、THNN、THCUNN)被编写成了独立的库,带有 C99 API。
这种配置是成熟的,我们已经使用了多年。
因此,PyTorch 非常高效——无论你需要运行何种尺寸的神经网络。
在 PyTorch 中,内存的使用效率相比 Torch 或其它方式都更加高效。我们为 GPU 编写了自定义内存分配器,以保证深度学习模型在运行时有最高的内存效率,这意味着在相同硬件的情况下,你可以训练比以前更为复杂的深度学习模型。
轻松拓展
编写新的神经网络模块,或与 PyTorch 的 Tensor API 相接的设计都是很直接的,不太抽象。
你可以使用 Torch API 或你喜欢的基于 numpy 的库(比如 Scipy)来通过 Python 写新的神经网络层。
如果你想用 C++ 写网络层,我们提供了基于 cffi(http://cffi.readthedocs.io/en/latest/)的扩展 API,其非常有效且有较少的样板文件。
不需要写任何 wrapper code。这里有一个示例:https://github.com/pytorch/extension-ffi
安装
二进制
-
Anaconda
conda install pytorch torchvision -c soumith
来自源
Anaconda 环境的说明。
如果你想要用 CUDA 支持编译、安装:
-
NVIDIA CUDA 7.5 或之上的版本
-
NVIDIA CuDNN v5.x
安装可选依赖包
export CMAKE_PREFIX_PATH=[anaconda root directory]
conda install numpy mkl setuptools cmake gcc cffi
conda install -c soumith magma-cuda75 # or magma-cuda80 if CUDA 8.0
安装 PyTorch
export MACOSX_DEPLOYMENT_TARGET=10.9 # if OSX
pip install -r requirements.txt
python setup.py install
开始使用
从以下三点开始学习使用 PyTorch:
-
教程:开始了解并使用 PyTorch 的教程(https://github.com/pytorch/tutorials)。
-
案例:跨所有领域的轻松理解 PyTorch 代码(https://github.com/pytorch/examples)。
-
API 参考:http://pytorch.org/docs/
交流
-
论坛:讨论实现、研究等(http://discuss.pytorch.org)
-
GitHub 问题反馈:bug 通知、特征要求、安装问题、RFC、想法等。
-
Slack:通常聊天、在线讨论、合作等(https://pytorch.slack.com/)。
-
邮件订阅没有骚扰信件、单向邮件推送 PyTorch 的重要通知。订阅:http://eepurl.com/cbG0rv。
发布和贡献
PyTorch 的发布周期(主版本)为 90 天。目前的版本是 v0.1.6 Beta,我们期望在发布前尽量减少 bug。如果你发现了错误,欢迎向我们提交:
https://github.com/pytorch/pytorch/issues
我们欢迎所有形式的贡献。如果你希望帮助解决 bug,请直接上手,无需多作讨论。
如果你愿意为 PyTorch 提供新功能、实用函数或核心扩展,请先开一个 issue 与大家讨论一下。请注意:在未经讨论的情况下提交的 PR 可能会导致退回,因为我们可能会采取不同的解决方式。
在下一个版本中,我们计划推出三大新功能:
-
分布式 PyTorch
(这里已经有一个尝试性的实现了:https://github.com/apaszke/pytorch-dist) -
反反向(Backward of Backward):在反向传播的过程中进行过程优化。一些过去和最近的研究如 Double Backprop 和 Unrolled GANs 会需要这种特性。
-
用于 autograd 的 Lazy Execution Engine:这将允许我们可以通过引入缓存和 JIT 编译器来优化 autograd 代码。
开发团队
PyTorch 是一个社区驱动的项目,由经验丰富的工程师和研究者开发。
目前,PyTorch 由 Adam Paszke、Sam Gross 与 Soumith Chintala 牵头开发。其他主要贡献者包括 Sergey Zagoruyko、Adam Lerer、Francisco Massa、Andreas Kopf、James Bradbury、Zeming Lin、田渊栋,Guillaume Lample、Marat Dukhan、Natalia Gimelshein 等人。