人类药丸!传说中 Adobe 最可怕的黑科技发布了
发布于 2016-11-08 23:55:39 | 170 次阅读 | 评论: 0 | 来源: 网友投递
Adobe
Adobe 创建于1982年,是世界领先数字媒体和在线营销方案的供应商。公司总部位于美国加利福尼亚州圣何塞,在世界各地员工人数约 7000名。Adobe 的客户包括世界各地的企业、知识工作者、创意人士和设计者、OEM 合作伙伴,以及开发人员。今天聊个碉堡的
就在几天前,那个开发p图应用photoshop的adobe公司,更新了一波新品。

还发布了首个基于深度学习的平台——
「Adobe Sensei」

(简单来说,这就是ai,sensei 利用了 adobe 长期积累的大量数据和内容,从图片到影像,能够帮助我们解决很多问题,将重复劳动变得自动化)
这样你就可以在几分钟内调好一个表情
Sensei 可以进行脸部自动编辑

(它可以在照片里自动查找到人脸以及人脸的各个部分,包括眉毛、嘴唇和眼睛,并且学习这些部位的位置,来让设计师们调整照片上人的表情,而不会看起来不自然或者怪异)
的确很强大!
不过,
这次真正能把我点燃的黑科技,是它——
Project VOCO
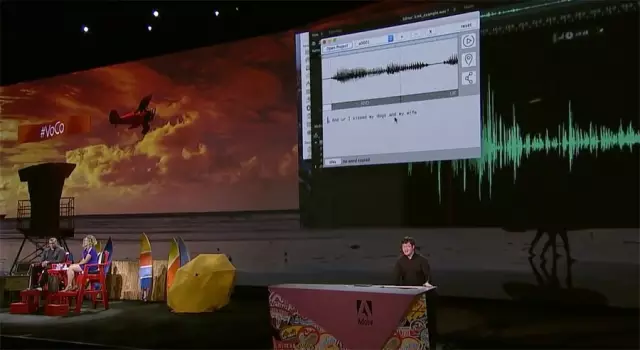
它的厉害之处。。
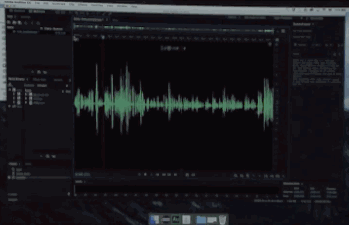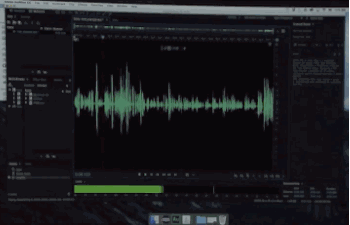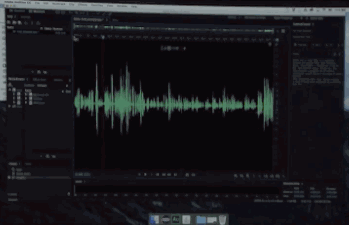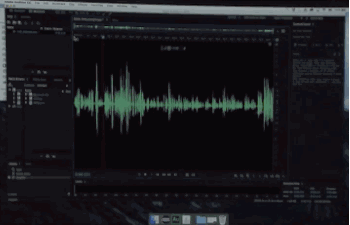
可以根据一个人说话的录音,合成几乎以假乱真的任意录音。
首先,让voco——
学会你的话
你丢一段大概20分钟你的音频让它学。
模仿你说话
比如这句:And ur I kissed my dogs and my wife.
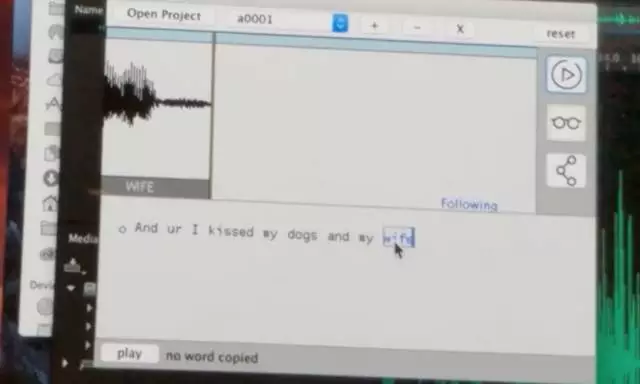
加新词和换位
你在这句中,不管调换词的位置、添加新词,音效完全听不出来有任何差异,几乎接近于完美模仿原发音者。
把 wife 换成 jordan
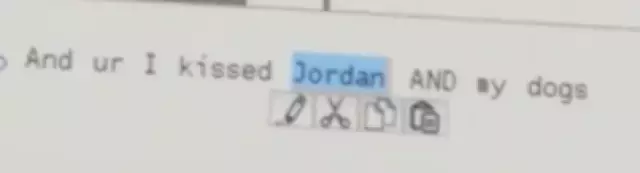
把 my dogs 换成 thre times

这简直就是音频编辑领域里的“Photoshop”。
这是现场的demo视频
呃,那么这样一来。。。真的就实现了“把话强加到别人身上了”。。。
看来柯南的变声器差不多可以出货了~

音频技术能如此,那么问题就来了——
既然
声音能以假乱真
那么
视频可以无中生有么
?
早在半年前,其实就已经实现了。
而且效果达到了可怕的真人秀级别。。。
可以这么说——
这软件一出,视频即将沦陷。
注意!下面你看到的——
都是假的!
老年痴呆版的川普

表情夸张的普京

猴子般的小布什

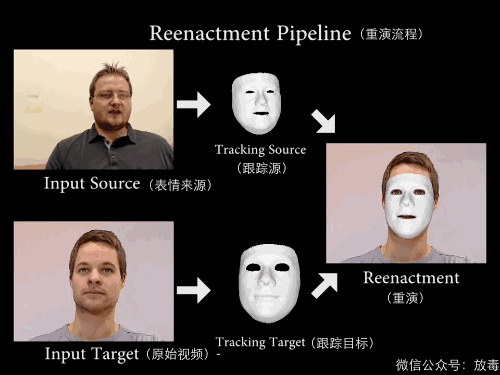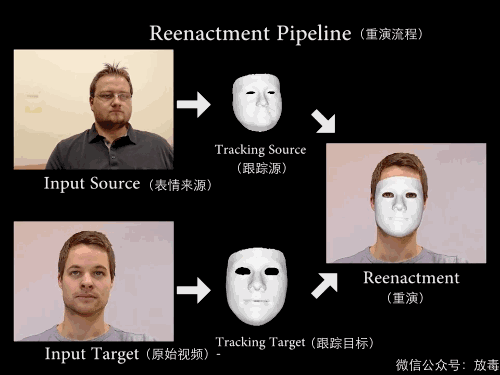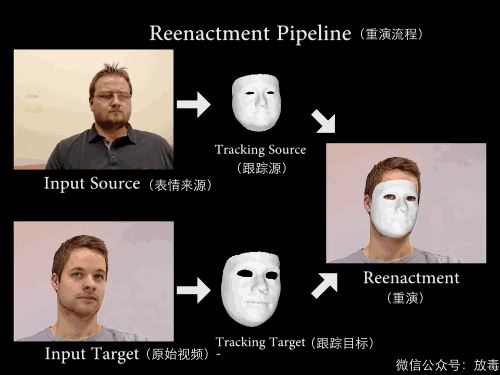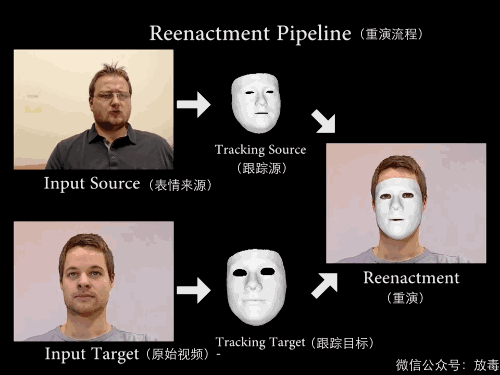
这是一项叫「Face2Face」的技术——
能实现实时面部重演(Real-time Facial Reenactment)。
“它可以实时捕捉使用者的表情,然后替换已有视频中人物的表情。”
把一个人的脸部RGB影像,通过算法,进行采集。
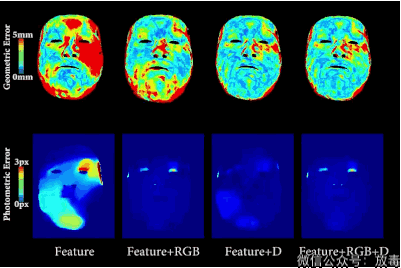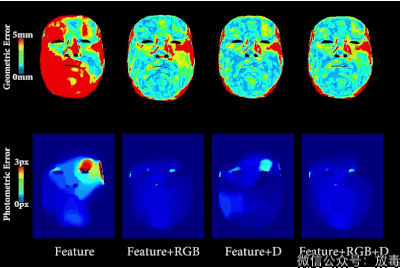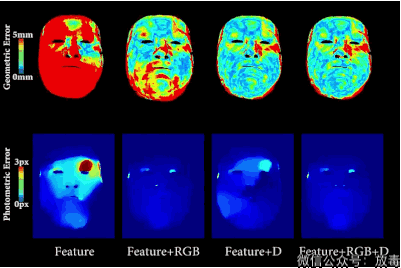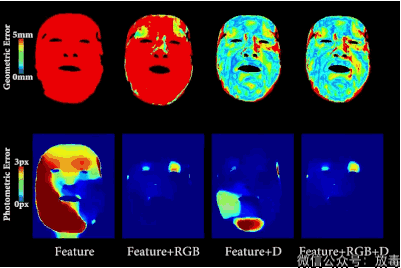
然后与另一个人的RGB数值进行比对,测算脸部五官结构。

最后就可以将主角的表情和口型无缝替换。
这样就能让他做从未做过的表情。
而你,只需要一个普通摄像头就能实现。。。
可怜的川普
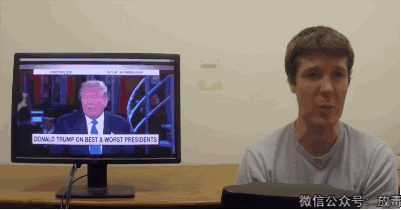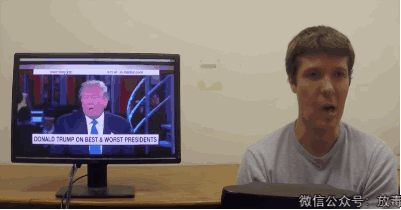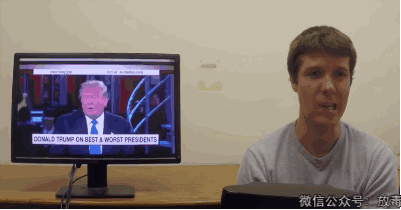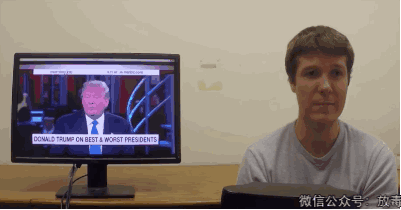
甚至——
可以在家帮奥巴马在白宫开个告别演说。

还是那句话——
你的思想有多远,你就可以有多变态!
你们有没有察觉这里面有个特别不对劲的地方。。。如果我们把voco和face2face这两个技术合起来的话。。。
你还是你吗?
呃,呵呵,人类药丸!