Ceph Upstream 添加 InfiniBand RDMA 互联支持
发布于 2016-10-21 11:28:36 | 193 次阅读 | 评论: 0 | 来源: 网友投递
Ceph PB 级分布式文件系统
Ceph是一个 Linux PB 级分布式文件系统。Ceph 最初是一项关于存储系统的 PhD 研究项目,由 Sage Weil 在 University of California, SantaCruz(UCSC)实施。
10月19日,国内软件定义存储企业XSKY开源了历时近1年时间研发的基于Ceph的IB RDMA互联支持,并且向Ceph社区提交了IB RDMA的协议栈代码。基于该部分代码,Mellanox研发部门表示也会参与其中,双方将共同孵化和完善基于AsyncMessenger的网络通信引擎,试图大幅度提升IO路径上的网络性能。此外,XSKY将协同一些企业用户基于此进行大规模Ceph集群测试。
XSKY从成立至今在Ceph社区当中一直围绕高性能方面积极贡献代码,此次将IB RDMA的开源将会对加速Ceph高性能的步伐产生极大意义。
RDMA(Remote Direct Memory Access)是通过利用硬件 Offload 能力,解决网络传输中的延迟,提供吞吐的技术。在高性能计算领域中, RDMA 被大量使用于网络数据传输与运算交互。
RDMA 定义了一种异步网络编程接口,称做 RDMA Verbs。应用程序主要于 Verbs 交互实现 RDMA 的优势。Verbs 掩盖了底层硬件差异,因此,无论 InfiniBand 还是以太网都可作为 Verbs 的后端,于是可实现RoCE(RDMA over Converged Ethernet)。
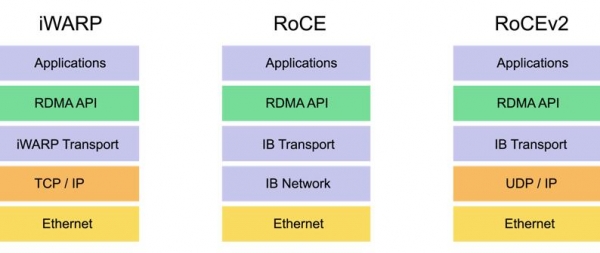
在 RDMA 的世界里,主要有几种协议簇。第一是 RDMA 之下的协议栈,如iWARP,RoCE,Infiniband HCA,RoCE v2 甚至 Software RoCE。这些主要是为RDMA提供底下的传输真实介质和链路实现。第二种是RDMA之上的应用协议,在存储领域包括iSER(iSCSI over RDMA),SMB 3 with SMB Direct,NFS/RDMA,SRP(SCSI over RDMA),以及现在最火热的NVMe over Fabric。
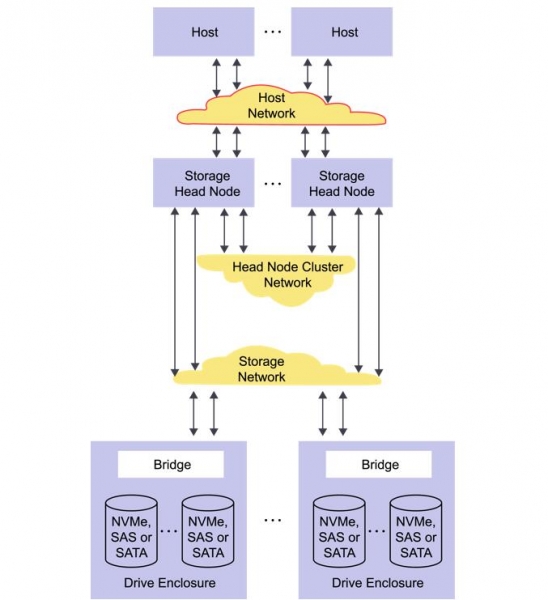
Host Network现在于NVMe Over Fabric的领域最为火热,如下图所示,Head Node Cluster Network和Storage Network 实际上作为传统存储机头的交换网络以及机头跟存储介质池的网络。前者过去通常是PCIe或者InfiniBand,后者通常是SAS或者Infiniband。在Ceph中,这两个也对应了 Ceph 的 Public Network 和 Cluster Network。
而在目前主流分布式软件定义存储里,仅华为公司的 FusionStorage 对外公开支持 InfiniBand/RDMA。而 Ceph 过去的 Infiniband/RDMA 虽然在社区被提及过,实际上是概念验证阶段,最大的原因也许是 Ceph 的网络接口以及规定语意比较复杂,使得在2014 年就已经进入主线的 XioMessenger(基于 AccelIO)至今未能满足Ceph核心对于网络层状态的需求而被投入应用。
今年在Raleigh举行 的 Ceph Next Day 上,有一个专门的话题,讨论 XioMessenger 无法满足 Ceph 语意的问题。主要在于 Ceph 所规定的 Messenger 语意和 Policy 太过复杂,使得非 TCP/IP 栈在无法充分测试的情况下,基本上很难达到要求。因此,为了解决 RDMA 进入 Ceph 的问题,主要发展出两个方向。第一个是降低 Ceph核心对于网络层状态的要求,减少 Messenger 需要实现的逻辑。但这个方向一开始就被开发者否决了,因为减少了Messenger的逻辑就意味着要增加其他地方的逻辑,改动量太大。第二个方向就是基于目前 AsyncMessenger 的框架(得益于之前 DPDK 的引入定义),扩展出不同的网络后端而无需关心上层会话逻辑。
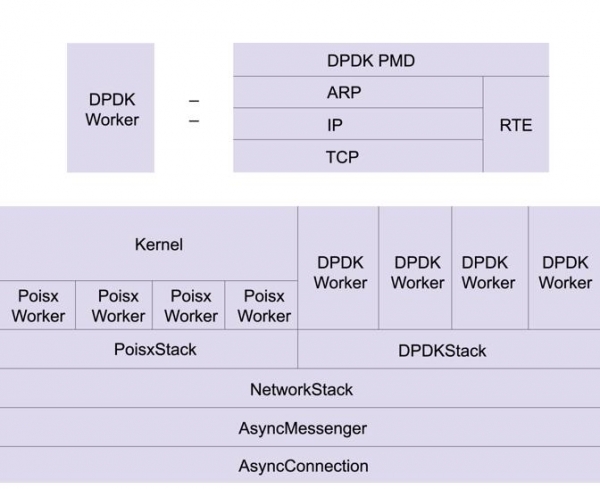
因此,基于 AsyncMessenger 的 RDMA 实现成为 Ceph 支持 RDMA 的计划。在最近一次跟社区的交互中,这个方向已经被社区领袖 Sage Weil 认为是正确的做法。
在10月19日,XSKY 正式把孵化出来的基于 AsyncMessenger 的 RDMA 网络引擎提交到 Ceph 社区,并开始进入 K 版本的 Pending 窗口。通过 AsyncMessenger 的 RDMA 网络引擎,最大优势是简单且高性能。不同于 XioMessenger 基于 AccelIO 的复杂抽象,该RDMA实现跟大多数RDMA应用一样直接采用原生的 Verbs 接口,充分整合到 Ceph 已有的框架中。大大降低了复杂度,提高了易用性。
至此,在一个版本周期内,Ceph将完成了整个网络层的大重构,从启用AsyncMessenger作为默认网络引擎,到释出DPDK+SPDK的网络栈,现在的RDMA引擎支持。使得Ceph在网络层面允许用户选择不同要求、性能的网络栈。
以上三种引擎,历时一年,多次更新并提交到社区,皆由XSKY团队发起并与硬件领导厂商Intel、Samsung、Mellanox等共同优化维护。三种网络引擎分别适配用户对于不同场景,不同特点的网络要求。之前Ceph结合DPDK+SPDK的实践,或代表了未来高速以太网的黄金配合,但最大的遗憾是需要等待Ceph BlueStore的成熟以及SPDK生态的稳定。但RDMA提供了合适的折中,在硬件配置较优的条件下,能够跟已有成熟的Ceph IO栈快速整合使用。
Red Hat 首席存储科学家Sage Weil在关于此次更新的意见中提到,“This definitely seems like a nice way to approach RDMA support since it doesn't require a full rewrite of the messenger protocol like msg/xio.”我们相信,这次RDMA之于Ceph upstream的变化在提升性能方面意义重大,虽然不能说这一网络层改进立即就适当应用于普通企业的生产,但通过社区和硬件领导厂商配合下的持续优化,可以期待Ceph效能再创新高不会太久。