如何评价百度刚刚开源的 Paddle 平台?
发布于 2016-08-31 23:57:02 | 256 次阅读 | 评论: 0 | 来源: 网友投递
百度(Baidu)中文搜索引擎
百度(Nasdaq简称:BIDU)是全球最大的中文搜索引擎,2000年1月由李彦宏、徐勇两人创立于北京中关村,致力于向人们提供“简单,可依赖”的信息获取方式。“百度”二字源于中国宋朝词人辛弃疾的《青玉案·元夕》词句“众里寻他千百度”,象征着百度对中文信息检索技术的执著追求。
百度开源了其深度学习平台Paddle,引发了挺多人工智能领域开发者的兴趣,包括一些之前一直在Tensorflow和Caffe上练手的开发者。不过鉴于深度学习的开源平台目前并不多,作为开发者也作为热心吃瓜群众的头等大事,就是想知道——这个平台怎么样?别人怎么看这个平台?以及这个平台跟Tensorflow以及Caffe有何区别?
这个平台本身怎么样
Paddle本身在开源前就一直存在,始于2013年的时候,因为百度深度实验室察觉到自己在深度神经网络训练方面,伴随着计算广告、文本、图像、语音等训练数据的快速增长,传统的基于单GPU的训练平台已经无法满足需求,为此在徐伟的带领下,实验室搭建了Paddle(Parallel Asynchronous Distributed Deep Learning)多机并行GPU这个训练平台。
但今天开源的Paddle当然不是3年前的简单模型,3年前Paddle可能还是一个独立的深度学习平台,不能很好地支持把数据从其他平台接入的需求。但今天的Paddle已经在处处强调,它的特色是让Spark与PADDLE耦合起来,是一个基于Spark的异构分布式深度学习系统。并且经过和百度相关业务的“紧密摩擦”后,它已经迭代了两个版本:从Spark on Paddle架构1.0版,到Spark on PADDLE 架构2.0版。根据平台开源的规则,大概是在百度内部用的非常得心应手,修复了一系列bug后,实验室才终于打算把Spark on PADDLE以及异构计算平台开源。至于百度为什么要开源,这个理由大家都懂的
深度学习平台目前还有很多bug——吸引更多的开发者来尝试和使用深度学习技术,对提高Paddle的档次是绝对有帮助的。
外界人士对这个平台的评价
知乎上贾清扬的回答,目前是比较正面的评价。
1. 很高质量的GPU代码
2. 非常好的RNN设计
3. 设计很干净,没有太多的abstraction,这一点比TensorFlow好很多。
4. 高速RDMA的部分貌似没有开源(可能是因为RDMA对于cluster design有一定要求):Paddle/RDMANetwork.h at master · baidu/Paddle · GitHub
5. 设计思路比较像第一代的DL框架,不过考虑到paddle已经有年头了,这样设计还是有历史原因的。
5.1 config是hard-code的protobuf message,这对扩展性可能会有影响。
5.2 可以看到很多有意思的类似历史遗留的设计:采用了STREAM_DEFAULT macro,然后通过TLS的方式定向到非default stream:Paddle/hl_base.h at 4fe7d833cf0dd952bfa8af8d5d7772bbcd552c58 · baidu/Paddle · GitHub (所以Paddle off-the-shelf不支持mac?)
5.3 在梯度计算上采用了传统的粗粒度forward/backward设计(类似Caffe)。可能有人会说“所以paddle没有auto gradient generation”,这是不对的,autograd的存在与否和op的粒度粗细无关。事实上,TensorFlow在意识到细粒度operator超级慢的速度以后,也在逐渐转回粗粒度的operator上。目前只看到这里。总之是一个非常solid的框架,百度的开发功底还是不错的。
估计不少人都读过贾清扬的评价,下面我们贴一个前百度数据工程师,极视角CTO缨宁的评价
看了一下,从设计理念来看和Caffe挺像的,但网络模型没有Caffe那么容易定义。最大贡献是做了分布式,提高了建立模型的速度。再详细的感受就得看代码和上手用了。
另一个跟上面两位观点反差较大的某研究深度学习的学者表示
Tensorflow的架构可以认为是一个升级版的theano, theano比Caffe还要早几年,只是Caffe最早train好了,同时发布了一些成功的卷积神经网络模型因此得到更多关注。Tensorflow和Caffe没啥太大的关系,可能借鉴了Caffe某一些实现技巧,本质上没啥关系。 百度这个很有可能是看到Caffe的成功之后实现的,很大程度模仿的Caffe, 同时试图修改一些东西使其看的和Caffe不一样。
我估计使用Caffe的人不会投向它,使用其他的工具的人(tensorflow, keras, theano, torch,mxnet)也不会投向它, 大家说几天然后就……一个月之后看一下它的github的关注量和github上能够找到的别人写的代码量你就知道他是否能有什么浪花(后面可以看看有没有人用他来参加kaggle或者其他比赛或在科研发布代码)。现在基本每个大公司都发布自己的深度学习框架(或者机器学习框架),例如微软, 亚马逊, 雅虎,好像都没有大动静。
这个平台跟Tensorflow以及Caffe有何区别
雷锋网(搜索“雷锋网”公众号关注)申请了Paddle的今天公测版本,目前还在审核中,虽然不能直接下载体验,但和其它两个平台的区别也不是毫无踪迹。根据我们之前对Caffe, Tensorflow的了解,以及今天Paddle放出的数据。
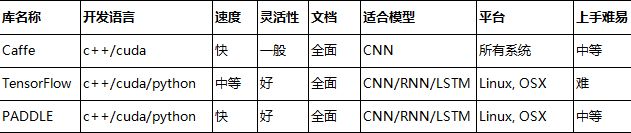
附接口语音
Caffe ——cmd, matlab, python
Tensorflow——python, c++
Paddle ——python, c++
(注:其中python是开发者主要使用的语言, 只有Caffe修改model内部的时候要用的c++。(如有异议,欢迎各开发者进一步交流)
总的来说
1)Caffe可以说是第一个工业级深度学习工具,始于2013年底由UC Berkely的贾杨清编写的具有出色的CNN实现功能的开发语言,在计算机视觉领域Caffe仍然是最流行的工具包。
Caffe的开发语言支持C++和Cuda,速度很快,但是由于一些历史性的遗留架构问题,它的灵活性不够强。而且对递归网络和语言建模的支持很差。Caffe支持所有主流开发系统,上手难度属于中等水平。
2)Tensorflow是Google开源的第二代深度学习技术,是一个理想的RNN API实现,它使用了向量运算的符号图方法,使得开发的速度可以很快。
Tensorflow支持的比较好的系统只有各种Linux系统和OSX,不过其对语言的支持比较全面,包含了Python、C++和Cuda等,开发者文档写得没有Caffe那么全面,所以上手比较难。
3)而此次百度的Paddle,作为基于Spark的异构分布式深度学习系统,通过使用GPU与FPGA异构计算提升每台机器的数据处理能力,暂时获得了业内“相当简洁、设计干净、稳定,速度较快,显存占用较小。”的评价,跟它通过使用GPU与FPGA异构计算提升每台机器的数据处理能力有重要联系。不过具体表现如何,还需等待几天观察一下大家的使用感受。
文章来自:雷锋网 宗仁