基于Lucene的Java搜索服务器Elasticsearch安装使用教程
发布于 2016-08-14 12:05:17 | 211 次阅读 | 评论: 0 | 来源: 网友投递
Apache Lucene全文检索引擎工具包
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Elasticsearch也是用Java开发的,并作为Apache许可条款下的开放源码发布,能够做到实时搜索,且稳定、可靠、快速,安装使用方便,这里我们就来看一下基于Lucene的Java搜索服务器Elasticsearch安装使用教程:
一、安装Elasticsearch
Elasticsearch下载地址:http://www.elasticsearch.org/download/
·下载后直接解压,进入目录下的bin,在cmd下运行elasticsearch.bat 即可启动Elasticsearch
·用浏览器访问: http://localhost:9200/ ,如果出现类似如下结果则说明安装成功:
{
"name" : "Benedict Kine",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.2.0",
"build_hash" : "8ff36d139e16f8720f2947ef62c8167a888992fe",
"build_timestamp" : "2016-01-27T13:32:39Z",
"build_snapshot" : false,
"lucene_version" : "5.4.1"
},
"tagline" : "You Know, for Search"
}
其中:
·name———Elasticsearch实例的名字,默认情况下它将从名字列表中随机选择一个,其设置是在config/elasticsearch.yml文件中;
·version———版本号,以json格式表示了一组信息,其中:
number字段代表了当前运行Elasticserch的版本号;
build_snashot字段代表了当前版本是否是从源代码构建而来;
lucene_version表示Elasticsearch所基于的Lucene的版本;
·tagline———包含了Elasticsearch的第一个tagline:"You Know, for Search"。
二、RTF版本
初学者可以首先从Elastisearch的RTF版本入手。RTF是Ready To Fly的缩写,这是一个集成了基本插件(如服务封装、中文分词、mapper-attachments、transport-thrift、tools.carrot2等插件)的并带有示例程序的可以直接上手的建议工程版本。
下载地址: https://github.com/medcl/elasticsearch-rtf
解压后会看到其目录结构。Elasticsearch包含的主要文件夹及功能如下(以TF版本为例):
·bin--包含运行Elasticsearch实例和管理插件的一些脚本;
·config--主要是一些设置文件
·lib--包含一些相关的包文件;
·plugins--包含相关的插件文件等;
·logs--日志文件;
·data--Elasticsearch中存放数据的地方;
·works--临时文件。
三、插件介绍及安装
1.Head
Head是一个用来监控Elasticsearch状态的客户端插件。
安装:到bin目录下 plugin install mobz/elasticsearch-head
安装后再浏览器中输入: http://localhost:9200/_plugin/head/ ,会打开如下界面:

图中显示了一个节点Benedict Kine,每个节点拥有不同index的数据,Head提供了HTTP客户端。
2.Marvel
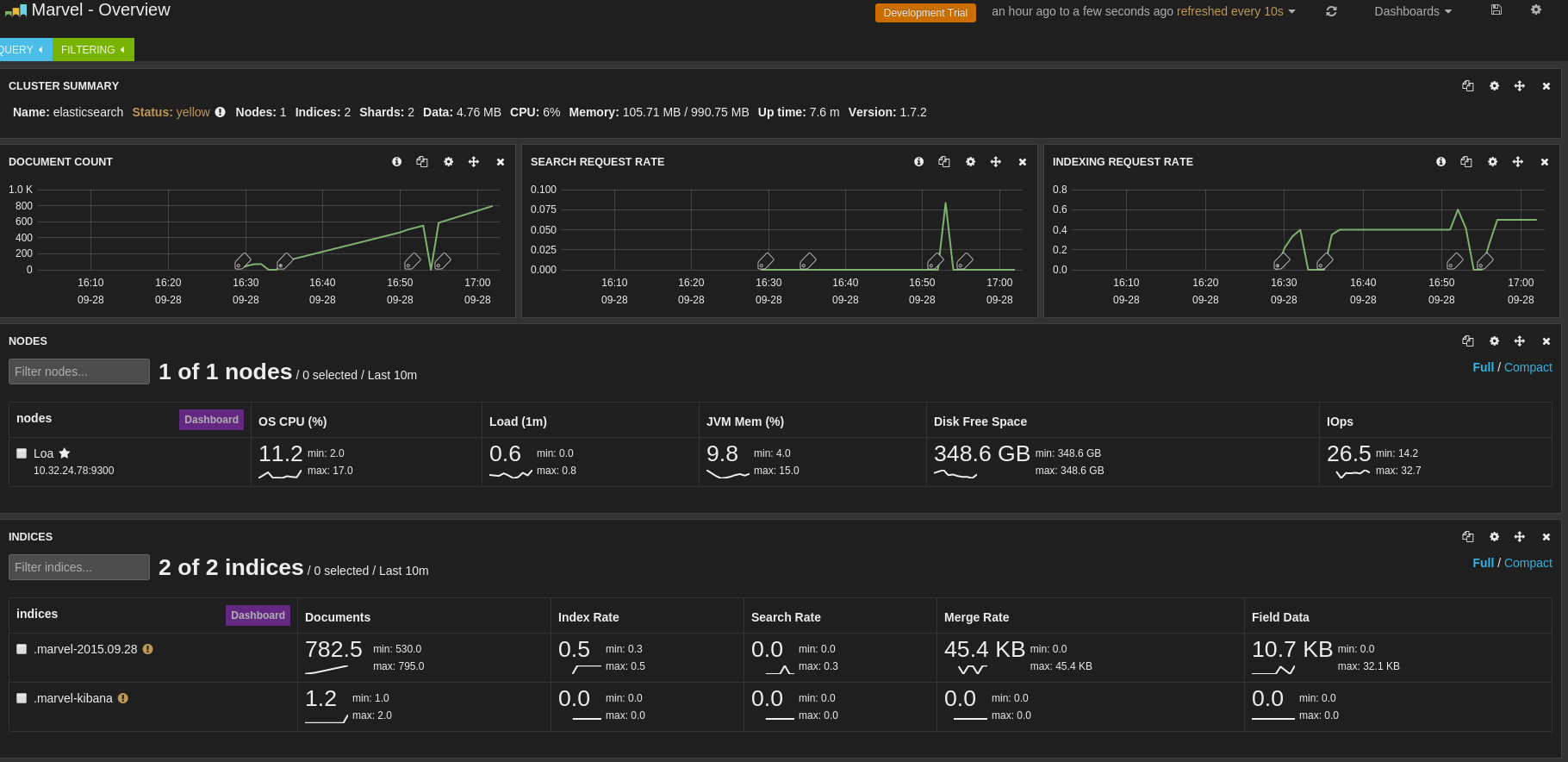
Marvel是Elasticsearch的图形化监控客户端,可以用来查看当前的各项状态。
安装:
marvel 是以 elasticsearch 的插件形式存在的,可以直接通过插件安装:
# ./bin/plugin -i elasticsearch/marvel/latest
如果你是从官网下载的安装包,则运行:
# ./bin/plugin -i marvel file:///path/to/marvel-latest.zip
运行:
在浏览器中输入:http://localhost:9200/_plugin/marvel/ ,会打开如下界面:
二、借助Head构建索引
启动Elasticsearch后,在浏览器中访问:http://localhost:9200/_plugin/head/ 打开Head工具。
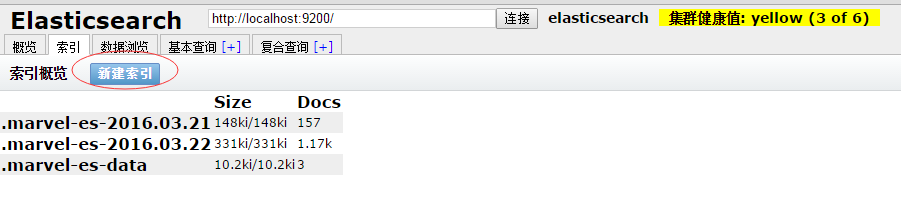
step1:
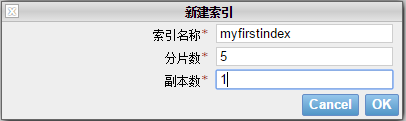
单击“新建索引”按钮来创建一个新的索引,在弹出框中输入索引名称,如下图所示。分片数为5依次为0,1,2,3,4。数据副本为1,
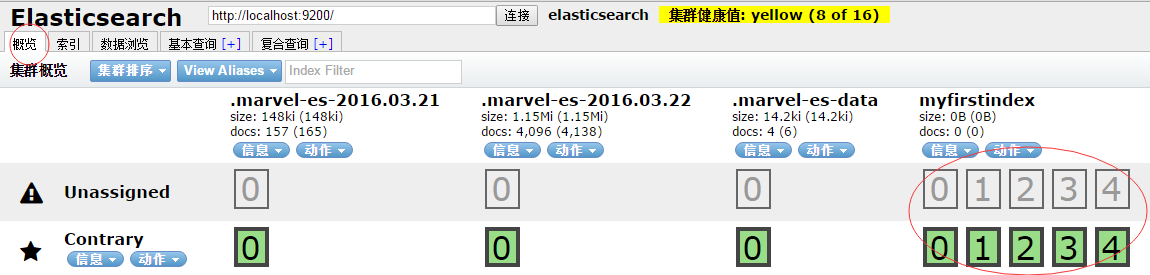
在概览中看到如下结果说明成功创建了索引。图中带有粗框的分片副本正是提供的数据副本,
step2:
在Head工具的“复合查询”(Any Request)标签下,打开“查询”(Query)选项,如下图所示。
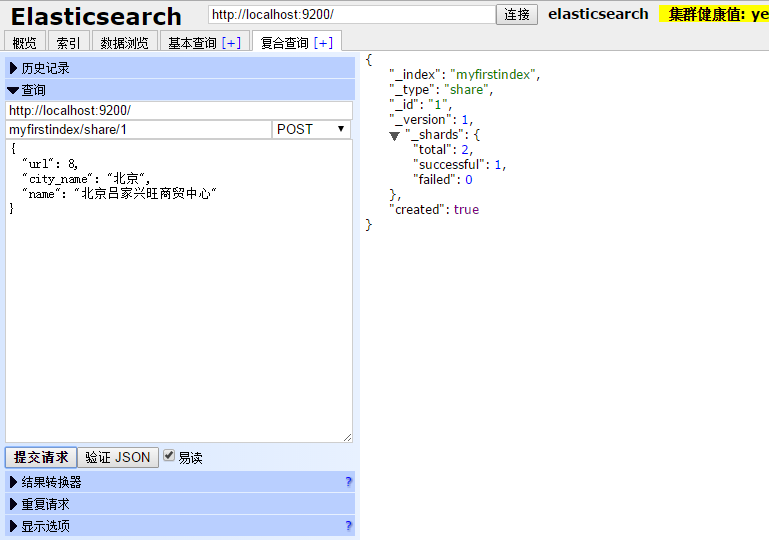
- 输入拟提交数据的索引文件名称(这里用刚刚建的索引文件名称myfirstindex)以及type(这里用share)、索引文档唯一标识符(即索引的id号,这里用1);
- 选择操作方式,这是选择POST,POST为相当于INSERT;
- 在文本框中输入拟添加的JSON数据;
- 提交后,就会在索引文件myfirstindex的类型文件share中,写入指定信息。如出现右侧内容则标识写入成功。
三、查询索引
还是在复合查询标签下,选择GET操作类型(相当于SELECT),如下图,就可以看到该索引文件的详细信息。

四、操作说明
Elasticsearch的Head中用到了HTTP协议的4种请求方法,其中:
- POST是向服务器提交数;
- GET是发送一个请求来取得服务器上的某一资源;
- PUT和POST都是向服务器发送数据,但PUT通常指定了资源的存放位置;
- DELETE是用来删除服务器上的某个资源。
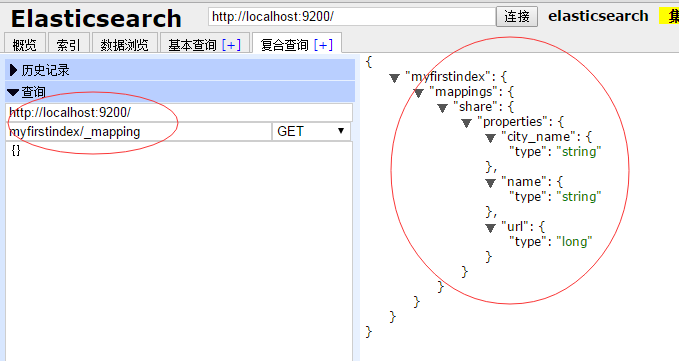
五、Mapping简述
Elasticsearch中的Mapping类似于静态语言中的数据类型。但是映像还有一些其他的含义,例如:执行一系列的指令,将输入的数据转成可搜索的索引项,使用映像可以查询类型文件的各个字段的信息。
六、信息检索
用户可以利用Head工具,通过HTTP传递参数的方式来构造一个简单的信息检索语句。如下图,指定在myfirstindex索引的share中,搜索字段为city_name其值为北京的检索请求构建方式。
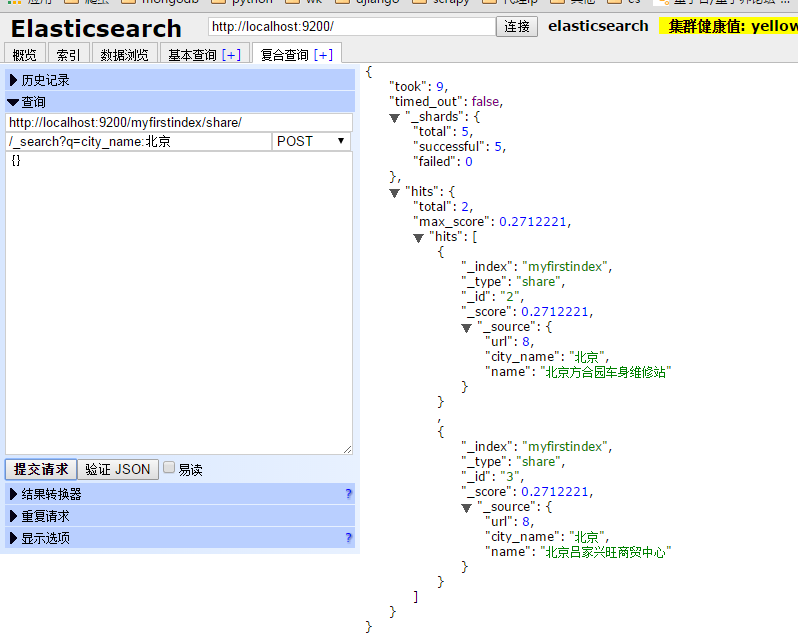
图的右侧的hits中可以看到返回的结果,hits表示命中的检索集合,total表示命中2条记录,max_score是其评分。
URL构建查询语句时,_search表示搜索RESTful接口,q后代表查询条件,q后的=是基于Lucene语法的查询表达式。