Twitter 开源替代了Storm 的数据实时分析平台 Heron
发布于 2016-05-28 00:52:54 | 183 次阅读 | 评论: 0 | 来源: 网友投递
Heron 数据实时分析平台
Heron是Twitter开发设计的一个数据实时分析平台,目前已开源。
“去年才说Heron短时间内不会开源,这才一年时间就开源了。嘴上说着不要,身体倒是很诚实嘛~
去年,Twitter对外宣布了新的分布式流计算系统Heron,随后消息称Twitter已经用Heron替换了Storm。此举将吞吐量最高提升了14倍,单词计数拓扑时间延迟最低降到了原来的1/10,所需的硬件减少了2/3。
Twitter使用Storm实时分析海量数据已经有好几年了,并在2011年将其开源。该项目稍后开始在Apache基金会孵化,并在去年秋天成为顶级项目。Storm以季度为发布周期,并且向着人们期望的稳定版前进。但一直以来,Twitter都在致力于开发替代方案Heron,因为Storm无法满足他们的实时处理需求。
Twitter的新实时处理需求包括:“每分钟数十亿的事件;大规模处理具有次秒级延迟和可预见的行为;在故障情况下,具有很高的数据准确性;具有很好的弹性,可以应对临时流量峰值和管道阻塞;易于调试;易于在共享基础设施中部署。”
Karthik Ramasamy是Twitter Storm/Heron团队的负责人。据他介绍,为满足这些需求,他们已经考虑了多个选项:增强Storm、使用一种不同的开源解决方案或者创建一个新的解决方案。增强Storm需要花费很长时间,也没有其它的系统能够满足他们在扩展性、吞吐量和延迟方面的需求。而且,其它系统也不兼容Storm的API,需要重写所有拓扑。所以,最终的决定是创建Heron,但保持其外部接口与Storm的接口兼容。
拓扑部署在一个Aurora调度器上,而后者将它们作为一个由多个容器(cgroups)组成的任务来执行:一个Topology Master、一个Stream Manager、一个Metrics Manager(用于性能监控)和多个Heron 实例(spouts和bolts)。拓扑的元数据保存在ZooKeeper中。处理流程通过一种反压机制实现调整,从而控制流经拓扑的数据量。除Aurora外,Heron还可以使用其它服务调度器,如YARN或Mesos。实例运行用户编写的Java代码,每个实例一个JVM。Heron通过协议缓冲处理彼此间的通信,一台机器上可以有多个容器。
Twitter已经用Heron完全替换了Storm。前者现在每天处理“数10TB的数据,生成数10亿输出元组”,在一个标准的单词计数测试中,“吞吐量提升了6到14倍,元组延迟降低到了原来的五到十分之一”,硬件减少了2/3。
当被问到Twitter是否会开源Heron时,Ramasamy说“在短时间内不会,但长期来看可能。”
然而就在5月25日,Twitter正式宣布Heron开源。Twitter工程经理Karthik Ramasamy在博客上宣布了这一消息。

Heron的基本原理和方法:
实时流系统是在大规模数据分析的基础上实现系统性的分析。另外,它还需要:每分钟处理数十亿事件的能力、有秒级延迟,和行为可预见;在故障时保证数据的准确性,在达到流量峰值时是弹性的,并且易于调试和在共享的基础设施上实现简单部署。
为了满足这些需求,Twitter讨论出了几种方案,包括:扩展Storm、使用其他的开源系统、开发一个全新的平台。因为有几个需求是要求改变 Storm的核心架构,所以对它进行扩展需要一个很长的开发周期。其他的开源流处理框架并不能完美满足Twitter对于规模、吞吐量和延迟的需求。而且,这些系统也不能兼容Storm API——适应一个新的API需要重写几个topologies和修改高级的abstractions,这会导致一个很长的迁移过程。所以,Twitter决定建立 一个新的系统来满足以上提到需求和兼容Storm API。
Heron的特色:
Twitter开发Heron,主要的目标是增加性能预测、提高开发者的生产力和易于管理。

图1:Heron架构
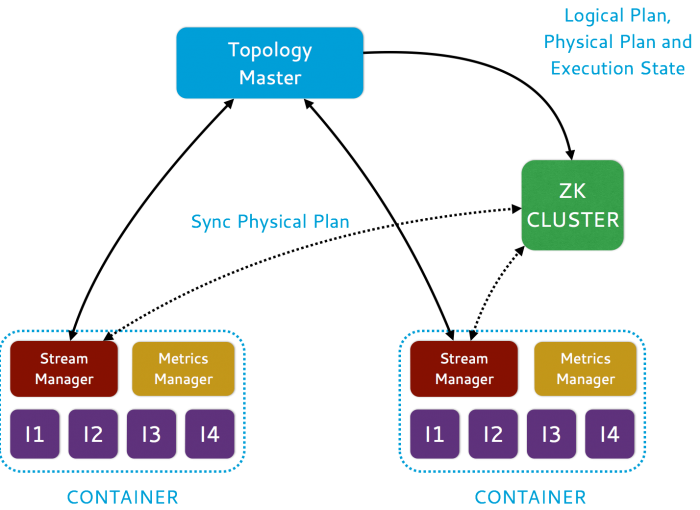
图2:拓扑架构
对于Heron的整体架构请看图1和图2。用户使用Storm API来构建和提交topologies来实现一个调度。调度运行的每一个topology作为一个job,有几个容器组成,其中一个容器运行主 topology,负责管理topology。每个剩余的容器运行一个流管理器,负责数据路由——一个权值管理器,用来搜集和报告各种权值和多个 Heron实例(运行user-defined spout/bolt代码)进程。这些容器是基于集群中的节点的资源可用性来实现分配和调度。对于topology元数据,例如物理计划和执行细节,都是 保管在Zookeeper中。
Heron的功能:
-
Off the shelf scheduler:通过抽象出调度组件,可轻易地在一个共享的基础设施上部署,可以是多种的调度框架,比如Mesos、YARN或者一个定制的环境。
-
Handling spikes and congestion:Heron 具有一个背压机制,即在执行时的一个topology中动态地调整数据流,从而不影响数据的准确性。这在流量峰值和管道堵塞时非常有用。
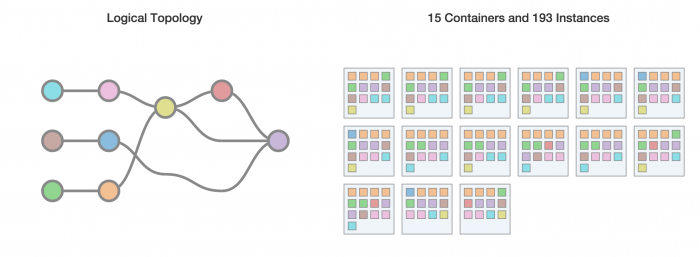
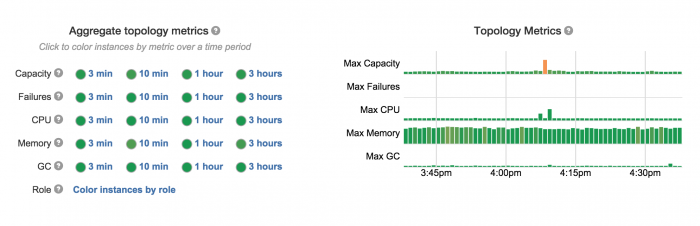
图3:Heron UI,显示逻辑计划、物理计划和拓扑状态
-
Easy debugging:每个任务是进程级隔离的,从而很容易理解行为、性能和文件配置。此外,Heron topologies复杂的UI如图3所示,可快速和有效地排除故障问题。
-
Compatibility with Storm:Heron提供了完全兼容Storm的特性,所我们无需再为新系统投资太多的时间和资源。另外,不要更改代码就可在Heron中运行现有的Storm topologies,实现轻松地迁移。
-
Scalability and latency:Heron能够处理大规模的topologies,且满足高吞吐量和低延迟的要求。此外,该系统可以处理大量的topologies。
Heron性能
比较Heron和Storm,样本流是150,000个单词,如下图所示:
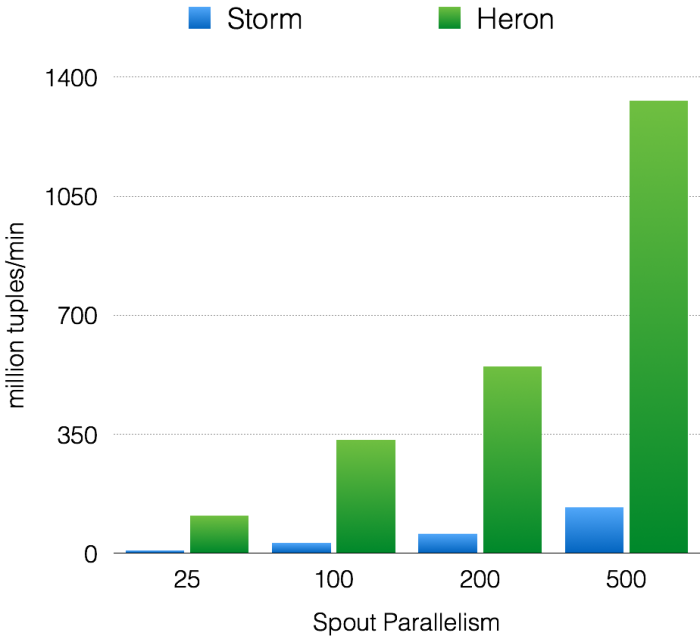
图4. Throughput with acks enabled
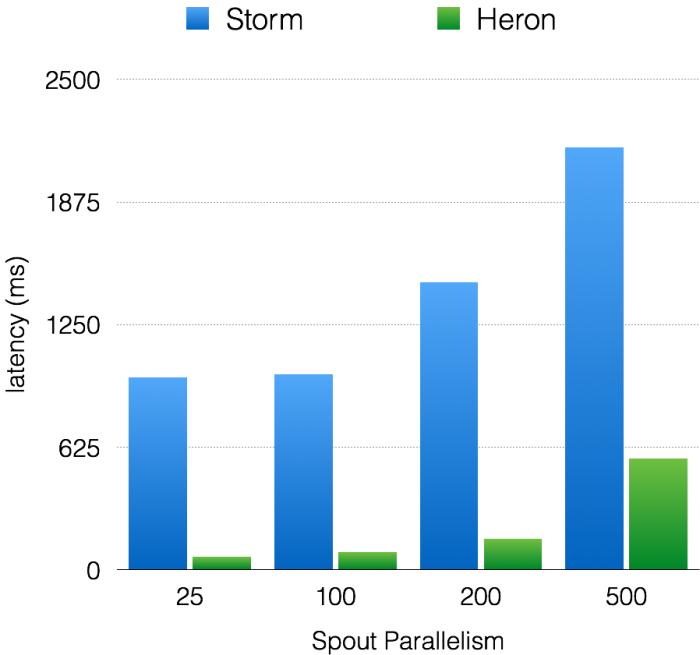
图5. Latency with acks enabled
如图4所示,Heron和Storm的吞吐量呈现线性增长的趋势。然而,在所有的实验中,Heron吞吐量比Storm高10–14倍。同样在端至端延迟方面,如图5所示,两者都在增加,可Heron延迟比Storm低5–15倍。
除此之外,Twitter已经运行topologies的规模大概是数百台的机器,其中许多实现了每秒产生数百万次事件的资源处理,完全没有问题。有了 Heron,众多topologies的每秒集群数据可达到亚秒级延迟。在这些案例中,Heron实现目标的资源消耗能够比Storm更低。
Heron at Twitter
在Twitter,Heron作为主要的流媒体系统,运行数以百万计的开发和生产topologies。由于Heron可高效使用资源,在迁移Twitter所有的topologies后,整体硬件减少了3倍,导致Twitter的基础设置效率有了显著的提升。
了解更多:https://blog.twitter.com/2015/flying-faster-with-twitter-heron