一位算法师工程师的Spark机器学习笔记:构建一个简单的推荐系统
发布于 2016-03-11 02:20:33 | 374 次阅读 | 评论: 0 | 来源: 分享
Apache Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。- 用户有海量选择:随着场景内item越来越多,用户越来越难以选择到合适的产品
- 个性化场景:在选择产品时,会借鉴那些与推荐用户相似地群体,利用群体智慧对用户进行推荐”千人千面”
在本篇博客中,会涉及到以下几个部分:
- 介绍不同类型的推荐引擎
- 使用用户偏好模型来构造推荐模型
- 使用训练好的模型来为指定user计算给定item的相似度大的items
- 使用标准的评测函数来构造推荐模型的好坏
推荐模型类别:
- 基于item的过滤:使用item的内容或者属性,选择给定item的相似的item列表,这些属性一般为文本内容,包括题目、名、标签以及一些产品的元信息,通常也包括一些media信息,比如图像、音频等等
- 协同过滤:协同过滤是一种集体智慧的推荐模型,在基于用户的协同过滤方法中,如果两个用户有相似的偏好(通过用户对物品的评分、用户查看物品的记录、用户对物品的评论),当为给定用户来推荐相关产品时,会使用其他相似偏好的用户的产品列表来对该用户进行推荐。基于item的协同过滤,一般数据组成为用户和用户对某些items的rating,产品被相似偏好的用户rating相同的趋势比较大,因而我们可以用所有用户对物品的偏好,来发现物品与物品之间的相似度,根据用户的历史偏好物品,根据相似信息来推荐给该用户
- Matrix Factorization
因为在Spark的MLlib模块中只有MF算法,文章之后会讲述如何使用Matrix Factorization来做相关的推荐。
Matrix Factorization
MF在Netflix Prize中得到最好的名词,关于MF的一片overview:http://techblog.netflix.com/2012/04/netflix-recommendations-beyond-5-stars.html。
Explicit matrix factorization
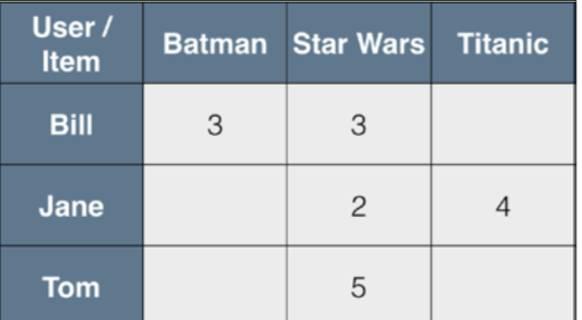
user ratings 数据:
Tom, Star Wars, 5Jane, Titanic, 4Bill, Batman, 3Jane, Star Wars, 2Bill, Titanic, 3
以user为行,movie为列构造对应rating matrix:
MF就是一种直接建模user-item矩阵的方法,利用两个低维度的小矩阵的乘积来表示,属于一种降维的技术。
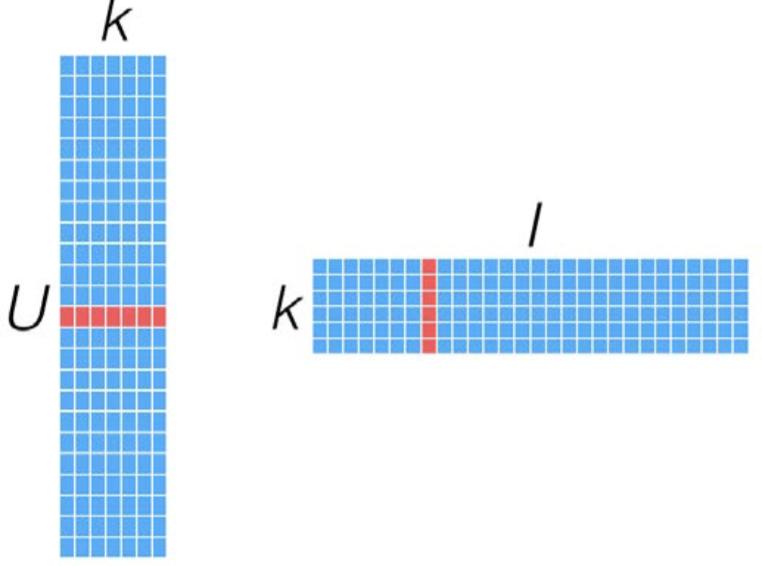
如果我们有U个用户,I个items,若不经过MF处理,它看来会使这样的:

是一个极其稀疏的矩阵,经过MF处理后,表示为两个维度较小的矩阵相乘:

这类模型被称为latent feature models,旨在寻找那些潜在的特征,来间接表示user-item rating的矩阵。这类潜在的features并不直接建模user对item的rating关系,而是通过latent features更趋近于建模用户对某类items的偏好,例如某类影片、风格等等,而这些事通过MF寻找其内在的信息,无需items的详细描述(和基于content的方法不同)。
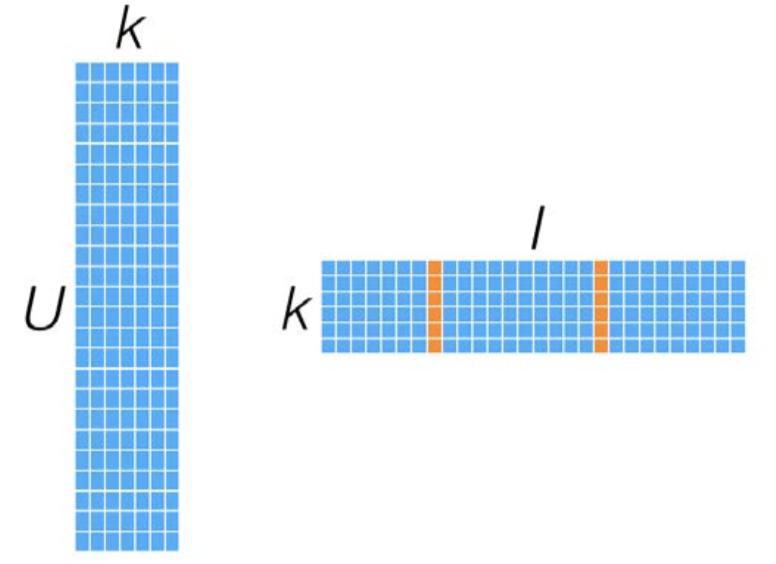
MF模型如何计算一个user对某个item的偏好,对应向量相乘即可:
如何计算两个item的相似度:
MF模型的好处是一旦模型创建好后,predict变得十分容易,并且性能也很好,但是在海量的用户和itemset时,存储和生产MF中的如上图的这两个矩阵会变得具有挑战性。
Implicit matrix factorization
前面我们都在讨论显式的一些偏好信息,比如rating,但是在大部分应用中,拿不到这类信息,我们更多滴搜集的是一些隐性的反馈信息,这类反馈信息没有明确地告诉某个用户对某个item的偏好信息,但是却可以从用户对某个item的交互信息中建模出来,例如一些二值特征,包括是否浏览过、是否购买过产品、以及多少次看过某部电影等等。
MLlib中提供了一种处理这类隐性特征的方法,将前面的输入ratings矩阵其实可以看做是两个矩阵:二值偏好矩阵P和信心权重矩阵C;
举个例子:假定我们的网站上面没有设计对movie的rating部分,只能通过log查看到用户是否观看过影片,然后通过后期处理,可以看出他观看到过多少次某部影片,这里P来表示影片是否被某用户看过,C来描述这里的confidence weighting也就是观看的次数:
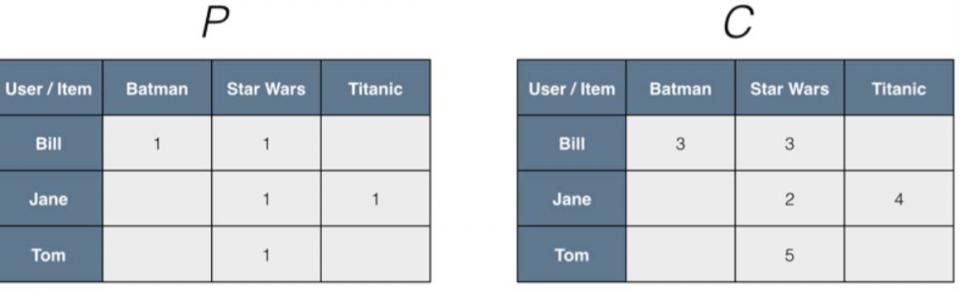
这里我们把P和C的dot product来替代前面的rating矩阵,那么我们最终建模来预估某用户对item的偏好
Alternating least squares
ALS是解决MF问题的一个优化技术,被证明高效、高性能并且能有效地并行化,目前为止,是MLlib中推荐模块的唯一一个算法。Spark官网上有专门地描述。
特征提取
特征提取是从已有数据中找到有用的数据来对算法进行建模,本文中使用显式数据也就是用户对movie的rating信息,这个数据来源于网络上的MovieLens标准数据集,以下代码为《Machine Learning with Spark》这本书里面的python的重写版本,会有专门的ipython notebook放到github上。
rawData = sc.textFile(“../data/ML_spark/MovieLens/u.data”) print rawData.first rawRatings = rawData.map(lambda x: x.split(‘t’)) rawRatings.take(5)
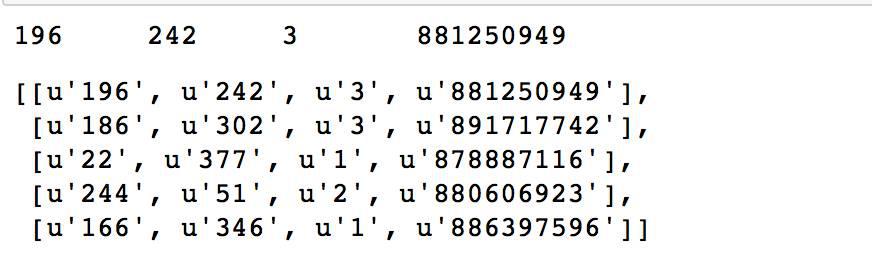
数据分别是userId,itemId,rating和timestamp。
from pyspark.mllib.recommendation import Rating from pyspark.mllib.recommendation import ALS ratings = rawRatings.map(lambda x : Rating(int(x[0]),int(x[1]),float(x[2]))) print ratings.first
格式化数据,用于后面建模数据,导入Rating,ALS模块,下面是ALS类的使用说明:
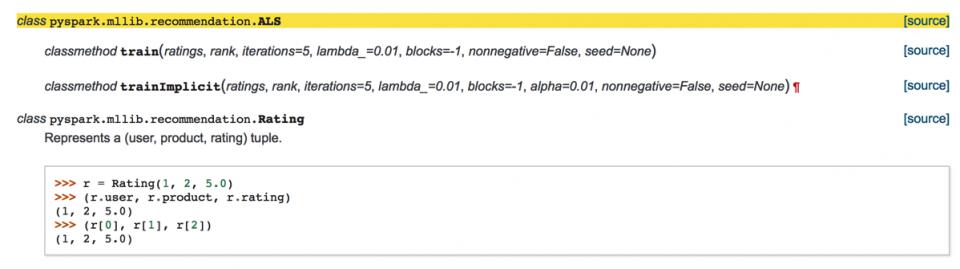
其中rank就是上面latent feature model中矩阵的k,在下面的实验中,我们设为50:
model = ALS.train(ratings,50) # modelImplicit = ALS.(ratings,50,alpha=0.02) userFeatures = model.userFeatures print userFeatures.take(2)

这里user1与user2,均用50维的向量来表示,也就是上面U*k那个矩阵的每个向量
predictRating = model.predict(789,123) print predictRating
预测用户789对item 123的rating值,结果为3.76599662082。
topKRecs = model.recommendProducts(userId,K) for rec in topKRecs: print rec moviesForUser = ratings.groupBy(lambda x : x.user).mapValues(list).lookup(userId) # print moviesForUser for i in sorted(moviesForUser[0],key=lambda x : x.rating,reverse=True): print i.product # for # print moviesForUser
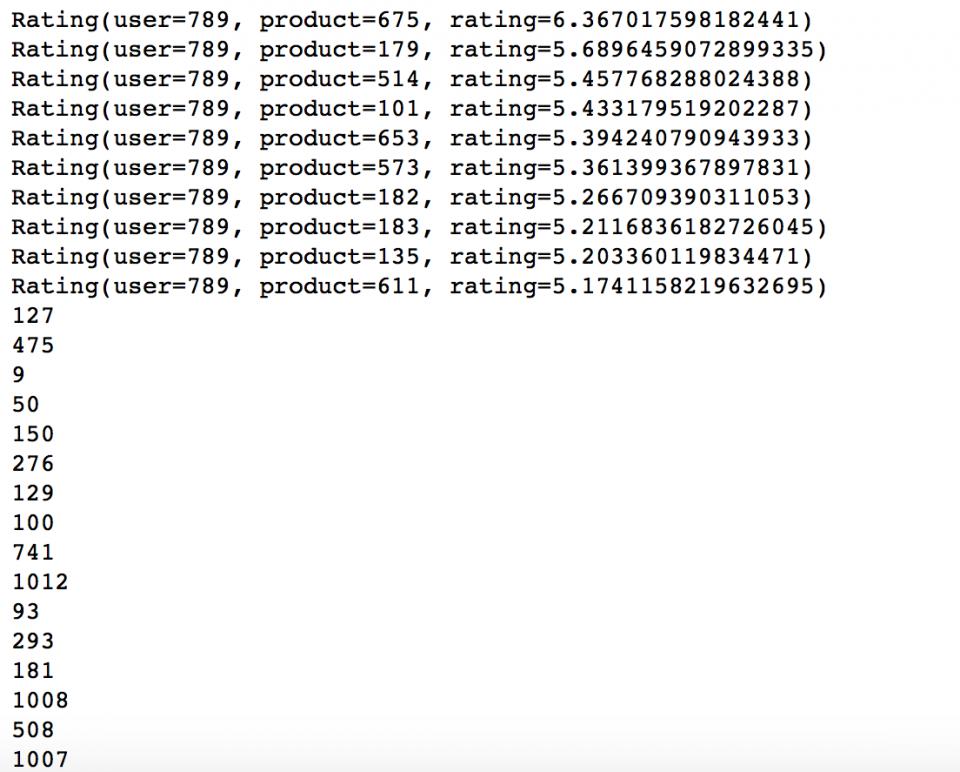
使用recommendProducts来为用户推荐top10的items,其items顺序为降序。MoviesForUser是从ratings数据中找出的用户789rating最高的数据,仔细看下发现数据和我们的ratings里面找出的数据貌似一个都没有相同的,那么是不是说明我们的算法不给力呢?!这个可不一定,想想看,如果推荐系统只是推荐给你看过的电影,那么它一定是一个失败的,并且完全对系统的kpi数据无提升作用,前面提到,MF的实质是通过latent feature去找到与用户过去偏好高的有某些隐性相同特征的电影(这些由整体用户的集体智慧得到),比如可能是某一类型的电影、又或者相同的演员等等,所以这里不能说明推荐系统不给力,但是确实也很难具有解释性。
Item recommendations
基于MF的方法中,我们可以利用之前看到k*I的矩阵,计算两个向量质检的相似性,也就是item的相似性。这样,可以很容易做相似商品推荐的场景。这里我们定义相似函数为余弦相似性:
import numpy as np def cosineSImilarity(x,y): return np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y))testx = np.array([1.0,2.0,3.0]) print cosineSImilarity(testx,testx)
然后,通过ALS建模的item的向量,拿到对应地item的向量表示:
itemId = 567 itemFactor = model.productFeatures.lookup(itemId)[0] # itemFactor = itemFactor[1] print itemFactor # model.productFeatures.collect sims = model.productFeatures.map(lambda (id,factor):(id,cosineSImilarity(np.array(factor), np.array(itemFactor))))sims.sortBy(lambda (x,y):y,ascending=False).take(10)
利用ALS的item向量拿到itemId为567的向量表示,然后对model的item的特征向量来计算与567的相似度,按降序排序并取top10
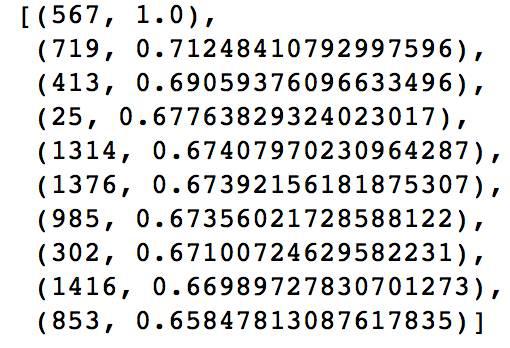
这样,可以找到与567这个item相似性最大的itemlist。
怎么判断我们生成的模型性能呢?常用的有一些比如Mean Squared Error,Root Mean Squared Error,但是这类标准无法考量推荐最终的items的排序问题,在实际工作中用的比较多的是Mean Average Precision,考虑到了item的排序造成的影响。
MSE&RMSE:
userProducts = ratings.map(lambda rating:(rating.user,rating.product)) print userProducts.take(1)[0] predictions = model.predictAll(userProducts).map(lambda rating:((rating.user,rating.product) ,rating.rating)) print predictions.take(5)ratingsAndPredictions = ratings.map(lambda rating:((rating.user,rating.product),rating.rating)) .join(predictions)
MSE = ratingsAndPredictions.map(lambda ((x,y),(m,n)):math.pow(m-n,2)).reduce(lambda x,y:x+y)/ratingsAndPredictions.count print MSE print math.sqrt(MSE)
先map ratings数据得到用户对item的组合,然后对这类数据predictAll计算该用户对item的rating估计值。然后利用join函数将预测的数据与ratings中的数据”联合”起来,塞入相似度函数进行计算,最终结果如下:
备注:看到这里肯定有人会问题,你之前在前面recommendProducts的,没有一个item是与ratings的数据相同,但是这里为什么又对比ratings中的评分信息来衡量推荐模型的好坏呢。猜想:recommendProduct是基于最终预测的ratings的高低来推荐的,但是,考虑到前面分析的原因,应该是不仅仅是按predict的rating的高低来给定推荐产品而是参入了其他的考量,所以这里并不矛盾。
APK:
什么是APK?可以看下这里,里面有R,Matlab,Python的各种Metrics的实现,还有kaggle里对APK的说明,逻辑很简单,相对于MSE和RMSE,考虑了推荐的排序对最后metrics的影响,如果检索出来的item排序越靠前,得分越高。
def avgPrecisionK(actual, predicted,k=10): if len(predicted)>k: predicted = predicted[:k] score = 0.0 num_hits = 0.0 for i,p in enumerate(predicted): if p in actual and p not in predicted[:i]: num_hits += 1.0 score += num_hits / (i+1.0) if not actual: return 1.0 return score / min(len(actual), k)itemFactors = model.productFeatures.map(lambda (id,factor):factor).collectitemMatrix = np.array(itemFactors)imBroadcast = sc.broadcast(itemMatrix)
拿到product的所有向量表示,初始化矩阵 ,然后broadcast到各个节点。
userVector = model.userFeatures.map(lambda (userId,array):(userId,np.array(array))) # print userVector[0] userVector = userVector.map(lambda (userId,x): (userId,imBroadcast.value.dot((np.array(x).transpose)))) userVectorId = userVector.map(lambda (userId,x) : (userId,[(xx,i) for i,xx in enumerate(x.tolist)])) sortUserVectorId = userVectorId.map(lambda (userId,x):(userId,sorted(x,key=lambda x:x[0],reverse=True))) sortUserVectorRecId = sortUserVectorId.map(lambda (userId,x): (userId,[xx[1] for xx in x]))
为每一个user推荐一个对应的item list,并按user向量与item向量相乘计算的该用户对该item的rating值来进行排序,最终给定一个有序的item的list。
userMovies = ratings.map(lambda rating: (rating.user,rating.product)).groupBy(lambda (x,y):x) userMovies = userMovies.map(lambda (userId,x):(userId, [xx[1] for xx in x] )) allAPK=sortUserVectorRecId.join(userMovies).map(lambda (userId,(predicted, actual)) :avgPrecisionK(actual,predicted,2000)) print allAPK.reduce(lambda x,y:x+y)/allAPK.count
然后从rating中找到对应的的item 列表,然后塞入之前我们写的apk函数,然后求平均,最终结果为0.115484271925。
当然我们可以直接使用MLlib内置的evaluation模块来对我们的模型进行评价,如MSE,RMSE:
from pyspark.mllib.evaluation import RegressionMetrics from pyspark.mllib.evaluation import RankingMetrics predictedAndTrue = ratingsAndPredictions.map(lambda ((userId,product),(predicted, actual)) :(predicted,actual)) # print predictedAndTrue.take(1) regressionMetrics = RegressionMetrics(predictedAndTrue) print “Mean Squared Error = %f”%regressionMetrics.meanSquaredError print “Root Mean Squared Error %f”% regressionMetrics.rootMeanSquaredError
MAP:
#MAP # The implementation of the average precision at the K function in RankingMetrics is slightly different # from ours, # so we will get different results. However, the computation of the overall mean average precision #(MAP, which does not use a threshold at K) is the same as our function if we select K to be very high # (say, at least as high as the number of items in our item set) sortedLabels = sortUserVectorRecId.join(userMovies).map(lambda (userId,(predicted, actual)) :(predicted,actual)) # print sortedLabels.take(1) rankMetrics = RankingMetrics(sortedLabels) print “Mean Average Precision = %f” % rankMetrics.meanAveragePrecision print “Mean Average Precision(at K=10) = %f” % rankMetrics.precisionAt(5)
这里结果与我们前面取k=2000的结果相同,说明我们的计算和MLlib是一致的,但是K=10或者比较小的值时,不一样,这是因为MLlib在precisionAt(k)这个函数与我们前面逻辑不同,这里我们不做考虑。
本章的代码放到了github上面,是ipython notebook的可以直接调用试用下,这版代码是我学习spark写的,水平很差,而且notebook中也没有基本的代码说明,算是对原书中这部分的scala的一次重写,喜欢python和spark的可以研究下,一步一步看下还是会熟悉python操作spark的流程的。