storm集群搭建
发布于 2016-01-02 22:07:32 | 192 次阅读 | 评论: 0 | 来源: PHPERZ
Apache Storm 分布式实时计算系统
Apache Storm 的前身是 Twitter Storm 平台,目前已经归于 Apache 基金会管辖。Apache Storm 是一个免费开源的分布式实时计算系统。简化了流数据的可靠处理,像 Hadoop 一样实现实时批处理。Storm 很简单,可用于任意编程语言。Apache Storm 采用 Clojure 开发。
集群环境:每台机器的操作系统,配置都要一样的,避免一些不必要的麻烦,
所需工具软件:python,zookeeper,jzmq,storm,ssh
1:集群环境准备:
1.1 设置主机名
(1)执行命令hostname hadoop0 该操作只对当前会话有效(2)编辑文件vi /etc/sysconfig/network 修改为hadoop0验证:重启linux,查看是否生效
1.2把ip和hostname绑定
编辑文件vi /etc/hosts 增加一行记录 192.168.80.100 hadoop0验证:ping hadoop0
1.3 关闭防火墙 执行命令service iptables stop 验证:service iptables status
1.4关闭防护墙的自动运行 执行命令chkconfig iptables off 验证:chkconfig --list | grep iptables
1.5 集群中每个节点时间同步
第一步:安装ssh,确保集群中各个节点都可以通信
1.6关闭selinux
查看selinux状态:
/usr/sbin/sestatus -v #如果selinux status参数为enabled即为开启状态
1.7关闭selinux服务器,
note:修改配置文件需要重启:
修改/etc/selinux/config文件:
将SELINUX=enforcing改成SELINUX=disabled
重启机器即可,
1.7:配置每个节点的ssh
在hadoop2和hadoop3上分别执行[object Object]
验证ssh的结果:
把hadoop1上的authorized_keys文件复制到hadoop2和hadoop3上,
执行scp authorized_keys hadoop2:/root/.ssh/
scp authorized_keys hadoop3:/root/.ssh/
ssh各个节点主机安装完毕,
在线安装mvn和ant
Linux下一键安装maven
wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
yum -y install apache-maven
安装ant
yum -y install ant
下载python wget http://www.python.org/ftp/python/
安装:
xz -d Python-2.7.6.tar.xz
tar xvf Python-2.7.6.tar
cd Python-2.7.6
./configure
make
make install
注意:
安装python之前,最好确认一下gcc是否安装。yum install -y gcc
否则./configure 阶段就会报错了
查看python version看看是否安装成功
安装zookeeper
6 搭建zk的集群
6.1 zk的集群要求至少3个节点(分别是hadoop0、hadoop1、hadoop2),且是奇数个,且节点之间的时间要同步。
6.2 在hadoop0上对zookeeper.tar.gz进行复制,解压缩、重命名、设置环境变量。
(1)复制zookeeper-3.4.5.tar.gz到/usr/local目录,然后进入到该目录
(2)执行命令 tar -zxvf zookeeper-3.4.5.tar.gz 进行解压缩(要进入到此文件目录下执行)
(3)重命名 mv zookeeper-3.4.5 zookeeper,然后vi /etc/profile文件,
配置环境变量
6.3 在hadoop0上进入zookeeper的conf目录
mv zoo_sample.cfg zoo.cfg
5.4 在hadoop0上进入/usr/local/zookeeper/conf目录下,进行编辑文件zoo.cfg,
修改dataDir=/tmp/zookeeper 改成 dataDir=/usr/local/zookeeper/data
新增以下三行
server.0=hadoop0:2888:3888
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
5.5 在hadoop0上创建文件夹,执行命令mkdir -p /usr/local/zookeeper/data
5.6 在hadoop0的data目录下,创建文件myid,文件内容是0
5.7 把hadoop0上的zookeeper文件夹和/etc/profile复制到hadoop1、hadoop2节点。
执行命令:
从新解压
5.8 在hadoop1上执行source /etc/profile,修改myid的值为1
在hadoop2上执行source /etc/profile,修改myid的值为2
5.9 ******************三个节点分别执行命令zkServer.sh start*******************
查看每个节点上的zookeeper状态:zkServer.sh status
5.10 验证:在各个节点分别执行jps,发现多一个java进程是QuorumPeerMain
5.11把zookeeper服务停用,zkServer.sh stop
好了,zookeeper集群配置好了
安装storm
解压apache-storm-0.9.4.tar.gz
tar -xvf apache-storm-0.9.4.tar.gz
建立软连接
ln -s apache-storm-0.9.4 storm
修改storm的配置文件storm.yaml文件
vim /usr/local/storm/conf/storm.yaml
vim /usr/local/storm/conf/storm.yaml :
storm.zookeeper.servers:
- "hostA"
- "hostB"
- "hostC"
storm.zookeeper.port: 2181
nimbus.host: "hostA"
storm.local.dir: "/tmp/storm"
storm.local.mode.zmq: true
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
说明:
storm.local.dir表示storm需要用到的本地目录。
nimbus.host表示那一台机器是master机器,即nimbus。
storm.zookeeper.servers表示哪几台机器是zookeeper服务器。
storm.zookeeper.port表示zookeeper的端口号,这里一定要与zookeeper配置的端口号一致,否则会出现通信错误,切记切记。当然你也可以配superevisor.slot.port,supervisor.slots.ports表示supervisor节点的槽数,就是最多能跑几个worker进程(每个sprout或bolt默认只启动一个worker,但是可以通过conf修改成多个)。
好了,storm集群就配置好了。
现在准备启动strom集群:
在主节点hostA上启动:
# bin/storm nimbus
# bin/storm supervisor
# bin/storm ui
在从节点上hostB hostC启动:
# bin/storm supervisor
然后就可以在http://{NimbusHost}:8080界面上看到storm ui的运行情况了。
如提交运行任务:
storm jar sendCloud-dataAnalysis.jar com.sohu.sendCloud.controller.SimpleTopology analysis_v1
至此,整个strom集群搭建完成。
其中要注意几点就是 storm的配置文件storm.yaml格式要非常仔细,严格按照官方教程配置:https://github.com/nathanmarz/storm/wiki/Setting-up-a-Storm-cluster
如 参数前面有空格,ip地址使用双引号之类的,配置不规范就会运行异常。
另外,如果使用的几台机器是有别名的,一定要在每一台机器上都做好所有机器的host,不然就会出现如下错误:
2012-11-15 10:54:38 ClientCnxn [INFO] Session establishment complete on server zw_125_228/*.*.*.228:2181, sessionid = 0x33afe9d0d4b0caf, negotiated timeout = 20000
2012-11-15 10:54:38 worker [ERROR] Error on initialization of server mk-worker
org.zeromq.ZMQException: Invalid argument(0x16)
at org.zeromq.ZMQ$Socket.connect(Native Method)
at zilch.mq$connect.invoke(mq.clj:74)
at backtype.storm.messaging.zmq.ZMQContext.connect(zmq.clj:61)
at backtype.storm.daemon.worker$mk_refresh_connections$this__4269$iter__4276__4280$fn__4281.invoke(worker.clj:243)
at clojure.lang.LazySeq.sval(LazySeq.java:42)
at clojure.lang.LazySeq.seq(LazySeq.java:60)
at clojure.lang.RT.seq(RT.java:473)
at clojure.core$seq.invoke(core.clj:133)
at clojure.core$dorun.invoke(core.clj:2725)
at clojure.core$doall.invoke(core.clj:2741)
at backtype.storm.daemon.worker$mk_refresh_connections$this__4269.invoke(worker.clj:237)
at backtype.storm.daemon.worker$fn__4324$exec_fn__1207__auto____4325.invoke(worker.clj:350)
at clojure.lang.AFn.applyToHelper(AFn.java:185)
at clojure.lang.AFn.applyTo(AFn.java:151)
at clojure.core$apply.invoke(core.clj:601)
at backtype.storm.daemon.worker$fn__4324$mk_worker__4380.doInvoke(worker.clj:322)
at clojure.lang.RestFn.invoke(RestFn.java:512)
at backtype.storm.daemon.worker$_main.invoke(worker.clj:432)
at clojure.lang.AFn.applyToHelper(AFn.java:172)
at clojure.lang.AFn.applyTo(AFn.java:151)
at backtype.storm.daemon.worker.main(Unknown Source)
2012-11-15 10:54:38 util [INFO] Halting process: ("Error on initialization")
而且这样的错误提示很不明显。
修改vim /etc/hosts 将每一台机器的别名都配置到hosts文件上,即可。
下面看一下运行的ui展示:
<a href="http://www.superwu.cn/wp-content/uploads/2014/11/clip_image002.jpg" class="cboxElement" rel="example4" 1329"="" style="text-decoration: none; color: rgb(1, 150, 227);">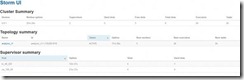
storm启动命令:
storm ui >/dev/null 2>&1 &
主节点启动:
storm nimbus >/dev/null 2>&1 &
从节点启动:
storm supervisor >/dev/null 2>&1 &
jps查看进程
[root@hadoop1 local]# jps
12273 QuorumPeerMain
15431 nimbus
15514 supervisor
15581 core
19732 Jps
[root@hadoop1 local]#
[root@hadoop2 local]# jps
6554 Jps
2779 supervisor
13518 QuorumPeerMain
[root@hadoop2 local]#
[root@hadoop3 ~]# jps
7165 Jps
11551 QuorumPeerMain
3442 supervisor
[root@hadoop3 ~]#
至此,storm集群搭建成功。
查看web界面:http://192.168.6.177:8080/index.html