ubuntu14.04安装Scrapy和redis时遇到的问题,及解决方法
发布于 2015-12-28 02:05:41 | 315 次阅读 | 评论: 1 | 来源: PHPERZ
Scrapy Python的爬虫框架
Scrapy是一个Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
准备好 Ubuntu14.04 System.
1. 安装 scrapy:
1) 按照这个 http://doc.scrapy.org/en/1.0/topics/ubuntu.html#topics-ubuntu
但是可能会遇到下面的问题:
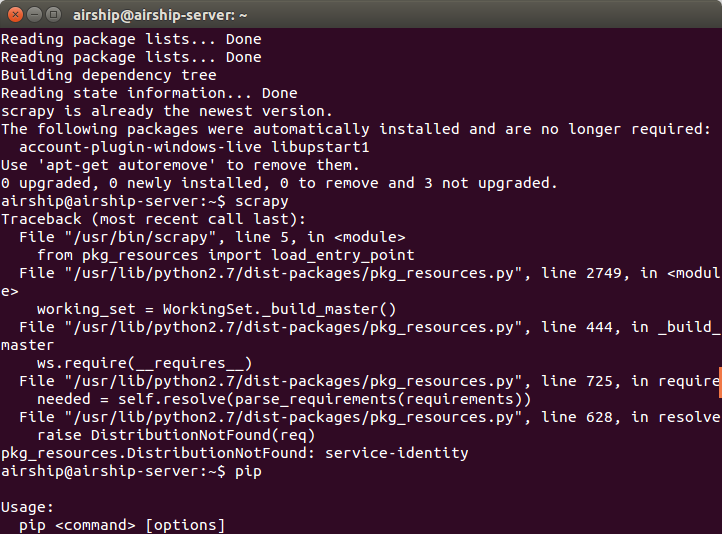
尝试了以下方式解决了该问题:
1>>sudo apt-get install python-pip【如果已经安装pip就不必操作此步】
2>>sudo pip install scrapy
2)另外,还有可能遇到pyasn1版本的问题:
解决方法:
1>>sudo apt-get install python-pip
2>>sudo pip install pyasn1 --upgrade
2. 安装 redis-server
1)按照 http://jingyan.baidu.com/article/948f592401d172d80ff5f99a.html
但是默认server绑定了本地IP,不支持远程访问,需要Redis服务器的配置文件redis.conf。
1)修改redis.conf:
sudo vi /etc/redis/redis.conf
2)注释bind:
#bind 127.0.0.1
3)修改后,重启Redis服务器:
sudo /etc/init.d/redis-server restart
【注意】:千万不要在windows下面修改之后再copy覆盖Ubuntu中的redis.conf,之前因为用SecureCRT,它对vi的支持不太好,所以用rz和sz命令把ubuntu中的文件下载到windows本地进行修改之后再上传覆盖,由于删掉了原来的文件,修改后的文件由于编码问题导致各种报错,最后redis崩溃了。尝试了各种方法均不好使,最后卸载了redis,由于存在某些文件的残留,导致redis安装失败。最后只能重装系统,重新开始。
经验教训:得到一个教训在做重要操作之前一定要备份,然后即使犯了错误,也可以返回到最后一次能正确运行的地方。