centos下Spark安装和使用
发布于 2015-02-05 01:33:20 | 1725 次阅读 | 评论: 0 | 来源: PHPERZ
Apache Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
本文主要为大家讲解的是 Spark 的安装过程和配置过程并测试 Spark 的一些基本使用方法。感兴趣的同学参考下。
安装环境如下:
- 操作系统:CentOs 6.5
- Hadoop 版本:CDH-5.3.0
- Spark 版本:1.2
关于 yum 源的配置以及 Hadoop 集群的安装,请参考 使用yum安装CDH Hadoop集群。
1. 安装
选择一个节点 cdh1 来安装 Spark ,首先查看 Spark 相关的包有哪些:
$ yum list |grep spark
spark-core.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6 @cdh
spark-history-server.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6 @cdh
spark-master.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6 @cdh
spark-python.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6 @cdh
spark-worker.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6 @cdh
hue-spark.x86_64 3.7.0+cdh5.3.0+134-1.cdh5.3.0.p0.24.el6 cdh
以上包作用如下:
- spark-core: spark 核心功能
- spark-worker: spark-worker 初始化脚本
- spark-master: spark-master 初始化脚本
- spark-python: spark 的 Python 客户端
- hue-spark: spark 和 hue 集成包
- spark-history-server
你可以根据你的集群部署规划来安装组件,在 cdh1 上安装 master,在 cdh1、cdh2、cdh3 上安装 worker:
# 在 cdh1 节点上运行
$ sudo yum install spark-core spark-master spark-worker spark-python spark-history-server -y
# 在 cdh2、cdh3 上运行
$ sudo yum install spark-core spark-worker spark-python -y
安装成功后,我的集群部署如下:
cdh1节点: spark-master spark-history-server
cdh2节点: spark-worker
cdh3节点: spark-worker
2. 配置
2.1 修改配置文件
设置环境变量,在 .bashrc 中加入下面一行,并使其生效:
export SPARK_HOME=/usr/lib/spark
可以修改配置文件 /etc/spark/conf/spark-env.sh,其内容如下,你可以根据需要做一些修改:修改 master 的主机名称。
# 设置 master 主机名称
export STANDALONE_SPARK_MASTER_HOST=cdh1
export SPARK_MASTER_IP=$STANDALONE_SPARK_MASTER_HOST
### Let's run everything with JVM runtime, instead of Scala
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_LIBRARY_PATH=${SPARK_HOME}/lib
export SCALA_LIBRARY_PATH=${SPARK_HOME}/lib
export SPARK_MASTER_WEBUI_PORT=18080
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=18081
export SPARK_WORKER_DIR=/var/run/spark/work
export SPARK_LOG_DIR=/var/log/spark
if [ -n "$HADOOP_HOME" ]; then
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
export HIVE_CONF_DIR=${HIVE_CONF_DIR:-/etc/hive/conf}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
### Comment above 2 lines and uncomment the following if
### you want to run with scala version, that is included with the package
#export SCALA_HOME=${SCALA_HOME:-/usr/lib/spark/scala}
#export PATH=$PATH:$SCALA_HOME/bin
如果你和我一样使用的是虚拟机运行 spark,则你可能需要修改 spark 进程使用的 jvm 大小(关于 jvm 大小设置的相关逻辑见 /usr/lib/spark/bin/spark-class):
export SPARK_DAEMON_MEMORY=256m
修改完 cdh1 节点上的配置文件之后,需要同步到其他节点:
scp -r /etc/spark/conf cdh2:/etc/spark
scp -r /etc/spark/conf cdh3:/etc/spark
2.2 配置 Spark History Server
执行下面命令:
$ sudo -u hdfs hadoop fs -mkdir /user/spark
$ sudo -u hdfs hadoop fs -mkdir /user/spark/applicationHistory
$ sudo -u hdfs hadoop fs -chown -R spark:spark /user/spark
$ sudo -u hdfs hadoop fs -chmod 1777 /user/spark/applicationHistory
在 Spark 客户端创建 /etc/spark/conf/spark-defaults.conf:
cp /etc/spark/conf/spark-defaults.conf.template /etc/spark/conf/spark-defaults.conf
在 /etc/spark/conf/spark-defaults.conf 添加两行:
spark.eventLog.dir=/user/spark/applicationHistory
spark.eventLog.enabled=true
如果想 YARN ResourceManager 访问 Spark History Server ,则添加一行:
spark.yarn.historyServer.address=http://HISTORY_HOST:HISTORY_PORT
最后,spark-defaults.conf 内容如下:
spark.master=spark://cdh1:7077
spark.eventLog.dir=/user/spark/applicationHistory
spark.eventLog.enabled=true
spark.yarn.historyServer.address=http://cdh1:19888
Spark History Server 中的 spark.history.provider 参数默认配置为 org.apache.spark.deploy.history.FsHistoryProvider 时,需要配置 spark.history.fs.logDirectory 参数,该参数在 spark-env.sh 中添加 SPARK_HISTORY_OPTS 环境变量:
#这里配置的是本地目录,也可以改为 hdfs 上的目录
export SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS -Dspark.history.fs.logDirectory=/var/log/spark"
如果,集群配置了 kerberos ,则还需要开启 kerberos 认证,涉及到下面三个参数:
spark.history.kerberos.enabled:是否开启 kerberos 认证spark.history.kerberos.principal:HistoryServer 的 kerberos 主体名称,注意:这里直接使用机器的hostname而不要使用_HOSTspark.history.kerberos.keytab:HistoryServer 的kerberos keytab文件位置
另外,还开启了 spark.history.ui.acls.enable (授权用户查看应用程序信息的时候是否检查acl),在 spark-env.sh 中继续添加:
export SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS -Dspark.history.kerberos.enabled=true -Dspark.history.kerberos.principal=spark/cdh1@LASHOU.COM -Dspark.history.kerberos.keytab=/etc/spark/conf/spark.keytab -Dspark.history.ui.acls.enable=true"
3. 启动和停止
使用系统服务管理集群
启动脚本:
# 在 cdh1 节点上运行
$ sudo service spark-master start
# 在 cdh1、cdh2、cdh3 节点上运行
$ sudo service spark-worker start
停止脚本:
$ sudo service spark-worker stop
$ sudo service spark-master stop
当然,你还可以设置开机启动:
$ sudo chkconfig spark-worker on
$ sudo chkconfig spark-master on
运行日志保存在 /var/log/spark,你可以通过 http://cdh1:18080/ 访问 spark master 的 web 界面。
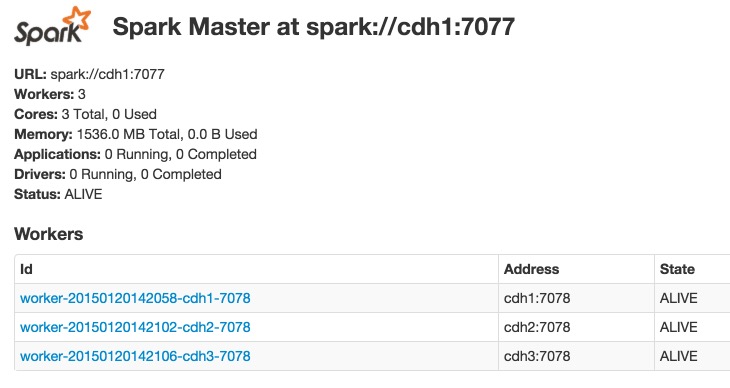
使用 spark 自带脚本管理集群
另外,你也可以使用 spark 自带的脚本来启动和停止,这些脚本在 /usr/lib/spark/sbin 目录下:
$ ls /usr/lib/spark/sbin
slaves.sh spark-daemons.sh start-master.sh stop-all.sh
spark-config.sh spark-executor start-slave.sh stop-master.sh
spark-daemon.sh start-all.sh start-slaves.sh stop-slaves.sh
这时候,还需要修改 /etc/spark/conf/slaves 文件:
# A Spark Worker will be started on each of the machines listed below.
cdh1
cdh2
cdh3
然后,你也可以通过下面脚本启动 master:
$ cd /usr/lib/spark/sbin
$ ./start-master.sh
通过下面命令启动所有节点上的 worker:
$ ./start-slaves.sh
当然,你也可以通过下面方式启动:
$ ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://cdh1:18080
4. 测试
4.1 运行测试例子
你可以在官方站点查看官方的例子。 除此之外,Spark 在发布包的 examples 的文件夹中包含了几个例子( Scala、Java、Python)。运行 Java 和 Scala 例子时你可以传递类名给 Spark 的 bin/run-example脚本, 例如:
$ ./bin/run-example SparkPi 10
通过 Python API 来运行交互模式:
# 使用2个 Worker 线程本地化运行 Spark(理想情况下,该值应该根据运行机器的 CPU 核数设定)
$ ./bin/pyspark --master local[2]
Python 2.6.6 (r266:84292, Nov 22 2013, 12:16:22)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ `_/
/__ / .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Python version 2.6.6 (r266:84292, Nov 22 2013 12:16:22)
SparkContext available as sc.
>>>
你也可以运行 Python 编写的应用:
$ mkdir -p /usr/lib/spark/examples/python
$ tar zxvf /usr/lib/spark/lib/python.tar.gz -C /usr/lib/spark/examples/python
$ ./bin/spark-submit examples/python/pi.py 10
另外,你还可以运行 spark shell 的交互模式:
# 使用2个 Worker 线程本地化运行 Spark(理想情况下,该值应该根据运行机器的 CPU 核数设定)
$ ./bin/spark-shell --master local[2]
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ `_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
scala> val lines = sc.textFile("data.txt")
scala> val lineLengths = lines.map(s => s.length)
scala> val totalLength = lineLengths.reduce((a, b) => a + b)
上面是一个 RDD 的示例程序,从一个外部文件创建了一个基本的 RDD对象。如果想运行这段程序,请确保 data.txt 文件在当前目录中存在。
4.2 在集群上运行
Spark 目前支持三种集群管理模式:
- Standalone – Spark自带的简单的集群管理器, 很容易的建立Spark集群
- Apache Mesos – 一个通用的集群管理器,可以运行Hadoop MapReduce和其它服务应用
- Hadoop YARN – Hadoop 2提供的管理器
另外 Spark 的 EC2 launch scripts 可以帮助你容易地在Amazon EC2上启动standalone cluster.
>
- 在集群不是特别大,并且没有 mapReduce 和 Spark 同时运行的需求的情况下,用 Standalon e模式效率最高。
- Spark可以在应用间(通过集群管理器)和应用中(如果一个 SparkContext 中有多项计算任务)进行资源调度。
Standalone 模式
该模式下只需在一个节点上安装 spark 的相关组件即可。
你可以通过 spark-shel l 运行下面的 wordcount 例子,因为 hdfs 上的输入和输出文件都涉及到用户的访问权限,故这里使用 hive 用户来启动 spark-shell:
读取 hdfs 的一个例子:
$ echo "hello world" >test.txt
$ hadoop fs -put test.txt /tmp
$ spark-shell
scala> val file = sc.textFile("hdfs://cdh1:8020/tmp/test.txt")
scala> file.count()
如果出现下面异常,可能是因为 系统可用内存不够:
/usr/lib/spark/bin/spark-shell: line 48: 5385 Killed "$FWDIR"/bin/spark-submit --class org.apache.spark.repl.Main "${SUBMISSION_OPTS[@]}" spark-shell "${APPLICATION_OPTS[@]}"
运行过程中,还可能会出现下面的错误:
14/10/24 14:51:40 WARN hdfs.BlockReaderLocal: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
14/10/24 14:51:40 ERROR lzo.GPLNativeCodeLoader: Could not load native gpl library
java.lang.UnsatisfiedLinkError: no gplcompression in java.library.path
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1738)
at java.lang.Runtime.loadLibrary0(Runtime.java:823)
at java.lang.System.loadLibrary(System.java:1028)
at com.hadoop.compression.lzo.GPLNativeCodeLoader.<clinit>(GPLNativeCodeLoader.java:32)
at com.hadoop.compression.lzo.LzoCodec.<clinit>(LzoCodec.java:71)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:249)
at org.apache.hadoop.conf.Configuration.getClassByNameOrNull(Configuration.java:1836)
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:1801)
at org.apache.hadoop.io.compress.CompressionCodecFactory.getCodecClasses(CompressionCodecFactory.java:128)
该异常的解决方法可以参考 Spark连接Hadoop读取HDFS问题小结 这篇文章。
解决方法:
cp /usr/lib/hadoop/lib/native/libgplcompression.so $JAVA_HOME/jre/lib/amd64/
cp /usr/lib/hadoop/lib/native/libhadoop.so $JAVA_HOME/jre/lib/amd64/
cp /usr/lib/hadoop/lib/native/libsnappy.so $JAVA_HOME/jre/lib/amd64/
更复杂的一个例子,运行 mapreduce 统计单词数:
$ spark-shell
scala> val file = sc.textFile("hdfs://cdh1:8020/tmp/test.txt")
scala> val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
scala> counts.saveAsTextFile("hdfs://cdh1:8020/tmp/output")
运行完成之后,你可以查看 hdfs://cdh1:8020/tmp/output 目录下的文件内容。
$ hadoop fs -cat /tmp/output/part-00000
(hello,1)
(world,1)
另外,spark-shell 后面还可以加上其他参数,例如:连接指定的 master、运行核数等等:
$ spark-shell --master spark://cdh1:7077 --cores 2
scala>
也可以增加 jar:
$ spark-shell --master spark://cdh1:7077 --cores 2 --jars code.jar
scala>
运行 spark-shell --help 可以查看更多的参数。
另外,也可以使用 spark-submit 以 Standalone 模式运行 SparkPi 程序:
$ spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode client --master spark://cdh1:7077 /usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar 10
Spark on Yarn
以 YARN 客户端方式运行 SparkPi 程序:
$ spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode client --master yarn /usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar 10
以 YARN 集群方式运行 SparkPi 程序:
$ spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode cluster --master yarn usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar 10
运行在 YARN 集群之上的时候,可以手动把 spark-assembly 相关的 jar 包拷贝到 hdfs 上去,然后设置 SPARK_JAR 环境变量:
$ hdfs dfs -mkdir -p /user/spark/share/lib
$ hdfs dfs -put $SPARK_HOME/lib/spark-assembly.jar /user/spark/share/lib/spark-assembly.jar
$ SPARK_JAR=hdfs://<nn>:<port>/user/spark/share/lib/spark-assembly.jar
5. Spark-SQL
Spark 安装包中包括了 Spark-SQL ,运行 spark-sql 命令,在 cdh5.2 中会出现下面异常:
$ cd /usr/lib/spark/bin
$ ./spark-sql
java.lang.ClassNotFoundException: org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
at java.net.URLClassLoader$1.run(URLClassLoader.java:202)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at java.lang.ClassLoader.loadClass(ClassLoader.java:306)
at java.lang.ClassLoader.loadClass(ClassLoader.java:247)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:247)
at org.apache.spark.deploy.SparkSubmit$.launch(SparkSubmit.scala:319)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:75)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Failed to load Spark SQL CLI main class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.
You need to build Spark with -Phive.
在 cdh5.3 中会出现下面异常:
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.cli.CliDriver
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 18 more
```
从上可以知道 Spark-SQL 编译时没有集成 Hive,故需要重新编译 spark 源代码。
### 编译 Spark-SQL
下载代码:
```bash
$ git clone git@github.com:cloudera/spark.git
$ cd spark
$ git checkout -b origin/cdh5-1.2.0_5.3.0
编译代码,集成 yarn 和 hive,有三种方式:
$ sbt/sbt -Dhadoop.version=2.5.0-cdh5.3.0 -Pyarn -Phive assembly
等很长很长一段时间,会提示错误。
改为 maven 编译:
修改根目录下的 pom.xml,添加一行 <module>sql/hive-thriftserver</module>:
<modules>
<module>core</module>
<module>bagel</module>
<module>graphx</module>
<module>mllib</module>
<module>tools</module>
<module>streaming</module>
<module>sql/catalyst</module>
<module>sql/core</module>
<module>sql/hive</module>
<module>sql/hive-thriftserver</module> <!--添加的一行-->
<module>repl</module>
<module>assembly</module>
<module>external/twitter</module>
<module>external/kafka</module>
<module>external/flume</module>
<module>external/flume-sink</module>
<module>external/zeromq</module>
<module>external/mqtt</module>
<module>examples</module>
</modules>
然后运行:
$ export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
$ mvn -Pyarn -Dhadoop.version=2.5.0-cdh5.3.0 -Phive -DskipTests clean package
如果编译成功之后, 会在 assembly/target/scala-2.10 目录下生成:spark-assembly-1.2.0-cdh5.3.0.jar,在 examples/target/scala-2.10 目录下生成:spark-examples-1.2.0-cdh5.3.0.jar,然后将 spark-assembly-1.2.0-cdh5.3.0.jar 拷贝到 /usr/lib/spark/lib 目录,然后再来运行 spark-sql。
但是,经测试 cdh5.3.0 版本中的 spark 的 sql/hive-thriftserver 模块存在编译错误,最后无法编译成功,故需要等到 cloudera 官方更新源代码或者等待下一个 cdh 版本集成 spark-sql。