linux下pig的安装
发布于 2014-12-11 11:13:59 | 399 次阅读 | 评论: 0 | 来源: PHPERZ
Apache Pig
Apache Pig 是一个高级过程语言,是基于hadoop的处理框,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。
本文为大家讲解的是如何在linux系统下安装pig的教程,感兴趣的同学参考下.
pig简介
Apache Pig 是一个高级过程语言,是基于hadoop的处理框,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。
1. pig有一套自己的处理语言,pig的处理过程要转化为MR运行
2.pig的数据处理语言是数据流的方式
3.pig的数据类型:int , long , float , double , chararray, bytearray, Map , Tuple , Bag
Hadoop简介
Hadoop是一个分布式系统基础架构,由Apache基金会所开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
hadoop与pig的版本:
hadoop-1.2.1
pig-0.12.1.tar.gz
安装pig
安装pig的过程十分简单:
将pig.xxx.tar.gz 拷贝到/usr下面
1.解压:
sudo tar -zxvf pig.xxx.tar.gz
2.重命名:
sudo mv pig.xxx. pig
3.修改配置文件(此处已经安装了很多框架)
sudo vim /etc/peofile
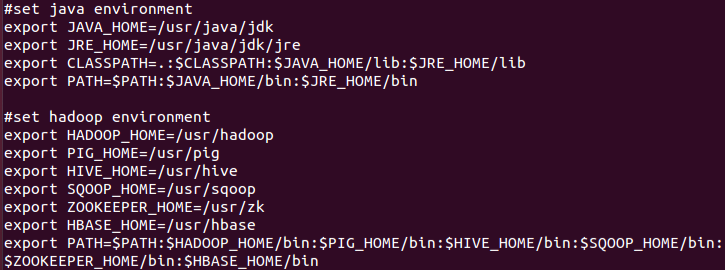
pig_home , path 的改变。
4 source /etc/peofile
5 编辑/usr/pig/conf/pig.properties
添加:

参照自己的hadoop的配置。
6.进入 bin/ pig 进入pig终端:

pig 正常起来。
7 quit 退出 grunt
8 自己实现使用pig处理数据。