2014百度招聘笔试题-软件研发工程师
发布于 2014-12-02 00:33:48 | 161 次阅读 | 评论: 0 | 来源: 网友投递
百度(Baidu)中文搜索引擎
百度(Nasdaq简称:BIDU)是全球最大的中文搜索引擎,2000年1月由李彦宏、徐勇两人创立于北京中关村,致力于向人们提供“简单,可依赖”的信息获取方式。“百度”二字源于中国宋朝词人辛弃疾的《青玉案·元夕》词句“众里寻他千百度”,象征着百度对中文信息检索技术的执著追求。
本言语为大家整理提供的是一份2014百度招聘笔试题-软件研发工程师,感兴趣的同学参考下.
一,简答题(本题共30分)
1. 当前计算机系统一般会采用层次结构来存储数据,请介绍下典型的计算机存储系统一般分为哪几个层次,为什么采用分层存储数据能有效提高程序的执行效率?(10分)
2. Unix/Linux系统的僵尸进程是如何产生的?有什么危害?如何避免?(10)
3. 简述Unix/Linux系统中使用socket库编写服务器程序的流程,请分别用对应的socket通信函数表示。
二,算法与程序设计题(本题共45分)
1, 使用C/C++语言写一个函数,实现字符串的反转,要求不能用任何系统函数,且时间复杂度最小。函数原型是:char *reverse_str(char *str)(15分)
2, 给定一个如下输入格式的字符串,(1,(2,3),(4,(5,6),7))括号内的元素可以是数字,也可以另一个括号,请实现一个算法消除嵌套的括号。比如把上面的表达式变成:(1,2,3,4,5,6,7),如果表达式有误请报错。(15分)
3, 相似度计算用于衡量对象之间的相似程度,在数据挖据,自然语言处理中使一个基础性
计算,在广告检索服务中往往也会判断网民检索Query和广告Adword的主题相似度。假设Query或者Adword的主题属性定义为一个长度为10000的浮点数据Pr[10000](称之为主题概率数组),其中Pr[i]表示Query或者Adword属于主题Id为i的概率,而Query和Adword的相似度简化定义为两者主题概率数组的内积,即sim(Query,Adword)=sum(QueryPr[i]*AdwordPr[i])(0<==i<10000).在实际应用场景中,由于大多数主题的概率都为0,所以主题概率数组往往比较稀疏,在实现时会以一个紧凑型数组topic_info_t[]的方式保存,其中100<=数组大小<=1000,并按照 topic_id递增排列,0<=topic_id<10000,0 ,0<topic_pr<1.
Struct topic_info_t{
Int topic_id;
Float topic_pr;
}
现在给出Query的topic_info_t数组和N(N>=5000)个Adwords的 topic_info-t数组,现要求出Query与Adwords的相似度最大值,即max(sim(Query,Adword[i])(0<=i<N).
Float max_sim(const vector& query_topic_info,
Const vector adwords_topic_info[],
Int adwords_number);
编写代码求时间复杂度最低的算法,并给出时间复杂度分析。(15分)
三,系统设计题(本题共25分)
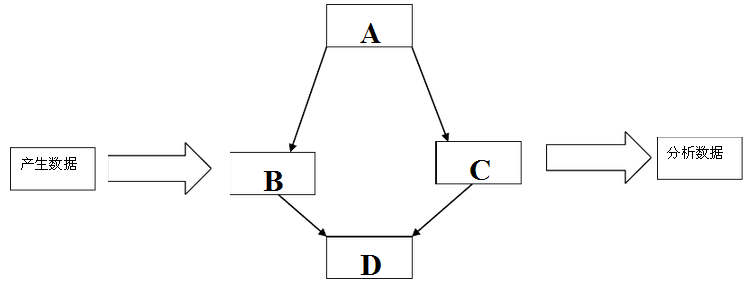
在企业中,对生产数据进行分析具有很重要的意义。但是生产数据通常不能直接用于数据分析,通常需要进行抽取,转换和加载,也就是业界常识的ETL.
生产数据

为了便于开发和维护,并提高数据实时性,通常将一个完整的ETL过程分析哼多个任务,组成流水线,如下图所示:
假设任务定义和任务之间的依赖关系都保存在文件中,文件格式分别如下:
表格1任务元数据
| 文件 | 格式 | 例子 |
| 任务定义文件 | 每行表示一个任务,3列: 1, ID 2, 开始运行时间 3, 最大运行时长(分钟) |
100,01:00:00,60 110,02:00:00,30 |
| 任务依赖关系 | 每行表示一个关系,2列: 1,前置任务 2, 后置任务 |
100,110 |
问题:
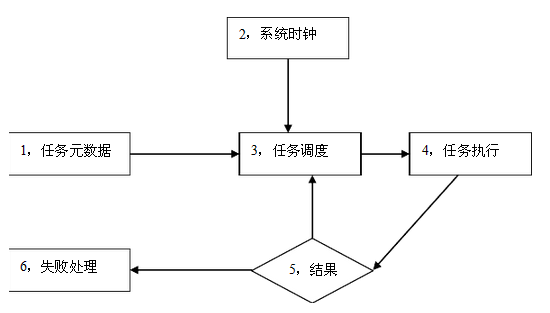
1, 下图是ETL调度系统的模块图。请描述各个模块的主要职责,以及各个线条的含义。(10分)
2, 添加依赖关系时要避免产生环,假设系统同一个时刻只允许一个人添加任务依赖,请实现一个函数来检查新的依赖是否导致环,如果该依赖的上游存在环会导致非正常的调度,因此也希望能避免。(10分)
a) 函数名:checkCycle
b) 输入:pairs,已存在的依赖关系((pre,post)),newPair新的依赖关系(pre,post)
c) 输出:True:不存在环,False:存在环
3, 如果调度时,某个任务在其依赖的任务之前执行,必然导致错误,请实现调度算法,确保任务按照依赖顺序执行?(10分)
a) 函数名 schedule
b) 输入1:tasks,整型数组
c) 输入2:tasks-relations,二元组数组,每个二元组表示一组关系
d) 输出:task_id序列,并行执行的用“,”分隔,其他的用“;”分隔
4, 给定一个任务,如何计算出他的最晚完成时间?(10分)
a) 函数名:calMaxEndTime
b) 输入1:tasks,3元组数组,(task_id,start_time,max_run_time);
c) 输入2:task-relations,2元组数组,每个二元组表示一组关系;
d) 输入3:task-id
e) 输出:最晚完成时间;