zookeeper的集群安装配置详解
发布于 2014-11-13 14:38:23 | 232 次阅读 | 评论: 0 | 来源: 网友投递
Apache ZooKeeper
ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
本文为大家讲解的是 zookeeper的集群安装配置详解,感兴趣的同学参考下。
ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
zookeeper是针对大型分布式系统的高可靠的协调系统。由此,我们可知,zookeeper是个协调系统,它的作用对象是分布式系统。那么,为什么分布式系统需要一个协调系统呢?原因如下:
开发分布式系统是件灰常困难复杂的事情,其中的困难主要体现在分布式系统的“部分失败”。“部分失败”是指信息在网络的两个节点之间传送的时候,如果网络出现了故障,发送者无法知道接收者是否收到了这个信息,而且这中故障的原因很复杂,接收者可能在出现网络错误之前已经接收到了信息,也可能没有收到,由或者接收者的进程死掉了。发送方能够获取真实情况的唯一办法是重新连接到接收方,询问接收方错误的原因,这就是分布式系统开发的“部分失败”的问题。
zookeeper就是解决分布式系统“部分失败”的框架。zookeeper不是让分布式系统避免“部分失败”问题,而是让分布式系统当碰到部分失败的时候,可以正确处理此类问题,让分布式系统能正常的运行。换言之,zookeeper是用来保证数据在zookeeper集群之间的事务性一致。
那么,该如何部署zookeeper的集群呢?
1、zookeeper服务器集群规模不小于3个节点,要求各个服务器之间系统时间保持一致。
2、下载zookeeper安装包,下载地址:http://zookeeper.apache.org/。
3、在hadoop1的/usr/local/目录下,解压缩安装包,并设置环境变量,如下图:
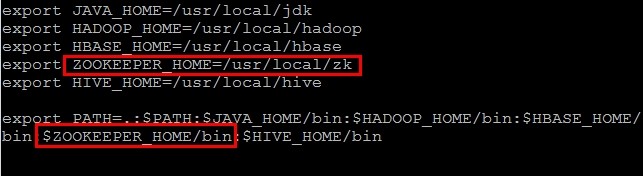
4、在conf目录下,重命名文件,如下图:

5、编辑文件,执行vi zoo.cfg
修改dataDir,如下:

新增:

6、创建目录,执行mkdir /usr/local/zk/data,并在该目录下创建文件myid,如下:

myid赋值为0。
7、把zk目录复制到hadoop2和hadoop3节点上,如下:

8、把hadoop2中myid的值修改为1,hadoop3中myid的值修改为2;
9、启动,在3个节点上分别执行命令zkServer.sh start,如下:
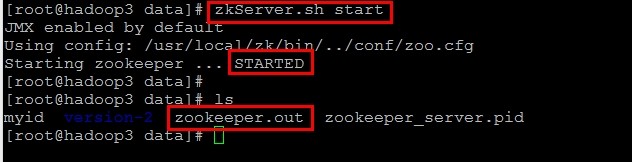
10、检验,在3个节点上分别执行命令zkServer.sh status,如下:


zookeeper的角色
1、领导者leader:负责投票的发起和决议,更新系统的状态;
2、学习着learner:包括跟随着follower和观察者observer,follower用于接收客户端的请求并向客户端返回结果,在选举过程中参与投票;
3、observer可以接收客户端的连接,将写请求转发给leader,但observer不参与投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取的速度;
4、客户端client:请求的发起方。