2014网易商业智能研究员面试题
发布于 2014-10-18 05:55:23 | 472 次阅读 | 评论: 0 | 来源: 网友投递
网易(163)
网易公司(NASDAQ:NTES),是中国领先的互联网技术公司,也是中国主要门户网站,和新浪网、搜狐网、腾讯网并称为“中国四大门户网站”。网易在开发互联网应用、服务及其它技术方面始终保持中国业内界的领先地位。
逻辑推理题
网易笔试已经过去好多天了,考完就放弃的,没想到十一来了竟然看到通过笔试,多少还是有点惊喜。于是回想起笔试时候那些不会的题,今天就来讲讲“3个学生 与教授的数字推理题”吧。昨晚睡觉前,感觉无聊,顿时灵感起来,故思得一解法,拿来与大家分享,如有不对还请指出。
题目复述:有个逻辑学教授和他3个非常聪明的学生A、B和C,教授在每个学生头上都贴了一个数字(整数),并且其中两个数字的和等于另一个,每个人能看到 别人头上的数字,而看不见自己的。教授让大家轮流猜自己头上的数字。第一轮,A说不知道,B说不知道,C也说不知道。教授让他们继续猜,A说不知道,B说 不知道,C说知道了,是144。请问其余两人头上的数字分别是多少?
求解:
首先,需要明确一个前提:C头上肯定是最大的那个数字,因为在一定程度上,头上非最大数字的两个人的信息量是永远等价的,要么同时猜出,要么同时猜不出,在之后的分析也可知,必然是数字最大的那人先猜出!
三个数字之间存在如下比例关系:N1:N2:N1+N2(N1和N2为正整数),不是一般性,我们假设A的为N1,B的为N2,C的为N1+N2。在此讨论数字的比例关系比绝对数字大小更清晰、易于理解。下面就是具体分析过程了:
(1)若N1=1,N2=1,即A、B和C的数字比例为1:1:2。A看到1和2,可能的选择是1和3,无法确定;B也是和A一样;C看到1和1,可能的选择只能是2(0的话不是正整数了),因此第一轮C就能猜出来。
(2)若N1=1,N2=2,即A、B和C的数字比例为1:2:3。A看到2和3,可能选择为1和5,无法确定;B看到1和3,可能选择为2和4;C看到 1和2,必然只能是3(因为假设C是1的话,那么从(1)可知B必然能猜出自己是2,而B没有说,所以假设不成立),因此第一轮C也能猜出来。、
(3)经分析,只有上述两种情况,能够第一轮猜出来,由题干可知,三个数字的关系必然不是(1)(2)的情况。
(4)若N1=1,N2=3,即A、B和C的数字比例为1:3:4。这时候3个聪明的学生心里都是知道(3)的分析结果的。A看到3和4,可能选择1和 7;B看到1和4,可能选择3和5;C看到1和3,在第二轮中必然只能是4(因为假设C是2的话,那么三个数字关系是1:2:3,由(2)可知第一轮就能 猜出来,所以假设不成立),因此这种情况下,C能够在第二轮首先猜出结果,这就对应着一组解:36+108=144。
(5)若N1=2,N2=3,即A、B和C的数字比例为2:3:5。A看到3和5,可能选择2和8;B看到2和5,可能选择3和7;C看到2和3,在第二 轮中必然只能选择5(因为假设C是1的话,三个数字成为1:2:3的关系,由(2)可知第一轮能够猜出,所以假设不成立),因此这种情况下,C能够在第二 轮首先猜出结果,也对应这一组解(但由于144不是5的倍数,不存在解)。
(6)经分析,在第二轮猜出结果只能是上述两种情况,因此此题解为36+108=144。不过让我们继续分析分析,看看该类型题的特点。
(7)若N1=1,N2=4,即A、B和C的数字比例为1:4:5。A和B都无法确定;C看到1和4,可能选择3或者5,而(1)和(2)无法排除这两个 结果,因此C也无法确定,也就是第二轮C也会说不知道。那么假设再继续第三轮的猜数字,那么聪明的三个学生都知道不可能是前面的(1、2、4、5)情况 了,那么C就能排除是3的情况,就能猜到是5。这种情况下,C必然是在第三轮首次猜到自己的数字。
(8)若N1=3,N2=4,结果与分析(7)一致。这样的分析可以一直继续下去,可以通解这类问题,可大致总结为:在第n轮C首次猜出自己的数字时,必然至少有两种情况能够满足,分别为1:n+1:n+2和n:n+1:2n+1。
综上所述,得到问题的通解。
——————————————————————————————————————————————————
补充一个网易互联网的笔试题目:
有数字:0 1 2 3 4 5 6 7 8 9,现在需要在之前的0~9每个数字下面填写一个数字,即:
_ _ _ _ _ _ _ _ _ _
要求满足:每个数字下面要填写的number正好是该数字在下面10个numbers中出现的次数。
解答:
(1)理解题意:
给出个例子:对数字 0 1 2 3 4,
下面的数字分别为 2 1 2 0 0,可知,数字0在下面出现的次数为2,所以下面对应的数字是2;1在下面出现1此,下面对应数字也是1;。。。
(2)解答该题:
设要填写的10个数字从左到右分别为A——J,解答过程如下所示:
- 0 1 2 3 4 5 6 7 8 9
- A B C D E F G H I J //需要满足A+B+...+J=10
- 9 - - - - - - - - 1 //假设J=1,可知A=9,但是0不能在下面出现9次
- 8 - - - - - - - 1 0 //J=0,假设I=1,可知A=8,但是B—H都不能取1
- 7 - - - - - - 1 0 0 //J=I=0,假设H=1,可知A=7,但是B-H都无法取值
- 6 2 1 0 0 0 1 0 0 0 //J=I=H=0,假设G=1,可知A=6,还差3,只需令B=2,C=1即可
算法题
1. 二叉树的中序遍历非递归实现
- void InOrderTraverse1(BiTree T) // 中序遍历的非递归
- {
- if(!T)
- return ;
- BiTree curr = T; // 指向当前要检查的节点
- stack<BiTree> s;
- while(curr != NULL || !s.empty())
- {
- while(curr != NULL)
- {
- s.push(curr);
- curr = curr->lchild;
- }
- if(!s.empty()) //当节点没有左儿子时,开始输出当前节点,同时将当前即当前节点更新为右儿子
- {
- curr = s.top();
- s.pop();
- cout<<curr->data<<" ";
- curr = curr->rchild;
- }
- }
- }
顺便补充下前序和后序遍历:
- void PreOrder_Nonrecursive(BiTree T) //先序遍历的非递归
- {
- if(!T)
- return ;
- stack<BiTree> s;
- s.push(T);
- while(!s.empty())
- {
- BiTree temp = s.top();
- cout<<temp->data<<" ";
- s.pop();
- if(temp->rchild) //右儿子先进栈
- s.push(temp->rchild);
- if(temp->lchild)
- s.push(temp->lchild);
- }
- //双栈法(后序是左——右——根,利用栈反下就是根——右——左,和前序遍历相似)
- void PostOrder_Nonrecursive(BiTree T) // 后序遍历的非递归
- {
- stack<BiTree> s1 , s2;
- BiTree curr ; // 指向当前要检查的节点
- s1.push(T);
- while(!s1.empty()) // 栈空时结束
- {
- curr = s1.top();
- s1.pop();
- s2.push(curr);
- if(curr->lchild) //由于s2负责输出,所以先左儿子进栈
- s1.push(curr->lchild);
- if(curr->rchild)
- s1.push(curr->rchild);
- }
- while(!s2.empty())
- {
- printf("%c ", s2.top()->data);
- s2.pop();
- }
- }
2. 输入N,输出是1~N的全排列,非递归实现
基本思想是:
1.对初始队列进行排序,找到所有排列中最小的一个排列Pmin(1,2,3, ... ,N)。
2.找到刚刚好比Pmin大比其它都小的排列P(min+1)。
3.循环执行第二步,直到找到一个最大的排列,算法结束。
如排列123456,这是所有排列中最小的一个排列,刚好比ABCDE大的排列是:123465。
算法如下:
给定已知序列P = (A1,A2,A3,.....,An)
对P按字典排序,得到P的一个最小排列Pmin = A1A2A3....An ,满足Ai > A(i-1) (1 < i <= n)
从Pmin开始,找到刚好比Pmin大的一个排列P(min+1),再找到刚好比P(min+1)大的一个排列,如此重复。具体方法如下:
1.从后向前(即从An->A1),找到第一对为升序的相邻元素,即Ai < A(i+1)。若找不到这样的Ai,说明已经找到最后一个全排列,可以返回了。
2.从后向前,找到第一个比Ai大的数Aj,交换Ai和Aj。
3.将排列中A(i+1)A(i+2)....An这个序列的数逆序倒置,即An.....A(i+2)A(i+1)。因为由前面第1、2可以得 知,A(i+1)>=A(i+2)>=.....>=An,这为一个升序序列,应将该序列逆序倒置,所得到的新排列才刚刚好比上个排列 大。
4.重复步骤1-3,直到返回。
举例如下:
当序列为162543,找到第一对逆序数为<2,5>,Ai=2;而第一个大于2的数为Aj=3,两者交换后序列为163542;将<542>倒置,序列为163245,刚好大于原序列。
- //将数组a中的下标i到下标j之间的所有元素逆序倒置
- void reverse(int a[],int i,int j)
- {
- for(; i<j; ++i,--j) {
- swap(a,i,j);
- }
- }
- //将数组中所以元素按序输出
- void print(int a[],int length)
- {
- for(int i=0; i<length; ++i)
- cout<<a[i]<<" ";
- cout<<endl;
- }
- //求取全排列,打印结果,可令a[]为[1,2,3,...,N],length=N
- void combination(int a[],int length)
- {
- if(length<2) return;
- bool end=false;
- while(true) {
- print(a,length); //输出数组a
- int i,j;
- for(i=length-2; i>=0; --i) { //找到不符合趋势的元素的下标i,即首次满足Ai<Ai+1
- if(a[i]<a[i+1]) break;
- else if(i==0) return; //找到最大的排列
- }
- for(j=length-1; j>i; --j) { //从后到前找到第一个满足Aj>Ai
- if(a[j]>a[i]) break;
- }
- swap(a,i,j); //交换Ai和Aj
- reverse(a,i+1,length-1); //转置Ai+1,...,An
- }
- }
补充下全排列的递归解法:
(A、B、C、D)的全排列为:(1)A后面跟(B、C、D)的全排列;(2)B后面跟(A、C、D)的全排列;(3)C后面跟(A、B、D)的全排列;(4)D后面跟(A、B、C)的全排列。
- template<typename T>
- void permutation(T array[], int begin, int end)
- {
- int i;
- if(begin == end){
- for(i = 0; i <= end; ++i){
- cout<<array[i]<<" ";
- }
- cout<<endl;
- return;
- } else {
- //for循环遍历该排列中第一个位置的所有可能情况
- for(i = begin; i <= end; ++i) {
- swap(array[i], array[begin]);
- permutation(array, begin + 1, end);
- swap(array[i], array[begin]);
- }
- }
- }
SQL题
1. 有个师徒关系表<师傅ID,徒弟ID>,一个师傅可以找多个徒弟,一个徒弟可以有多个师傅,现在已知一个师傅ID,要找和他有相同徒弟群(即所有徒弟都一样)的所有师傅。写SQL语句。
解答:
这是一个典型的“集合相等”问题。下面给一个例子说明思路:
假设有如下的师徒关系表t3。
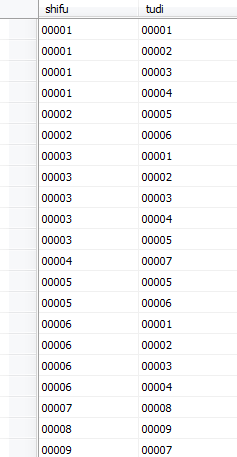
首先,我们找到有相同徒弟(非徒弟群)的师傅对(允许有重复),这个只要用inner join就行,得到的新表命名为表t4。
- select s1.shifu,s2.shifu from t3 s1 INNER JOIN t3 s2 ON
- (s1.tudi=s2.tudi and s1.shifu < s2.shifu)
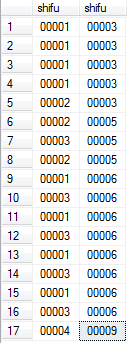
然后,留下这样的师傅对:该师傅对在新表t4中出现的行数 = 两个师傅在原始表t3中出现的行数,这样保证了留下的师傅对必定拥有相同的徒弟群,最后将相同的师傅对合并即可。需要使用到group by和having。
- select s1.shifu,s2.shifu from t3 s1 INNER JOIN t3 s2 ON
- (s1.tudi=s2.tudi and s1.shifu < s2.shifu) GROUP BY s1.shifu,s2.shifu
- HAVING count(*) = (select count(*) from t3 where s1.shifu=shifu)
- AND
- count(*) = (select count(*) from t3 where s2.shifu=shifu);
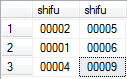
到此,就求得了拥有相同徒弟群的所有师傅对,那么要得到指定师傅ID的有相同徒弟群的师傅们,只要再select一下即可。
- select s3.shifu from t3 s3 where s3.shifu in(
- select sc.shifu_2 from
- (select s1.shifu as shifu_1,s2.shifu as shifu_2 from t3 s1 INNER JOIN t3 s2 ON
- (s1.tudi=s2.tudi and s1.shifu <> s2.shifu and s1.shifu='00004') GROUP BY s1.shifu,s2.shifu
- HAVING count(*) = (select count(*) from t3 where s1.shifu=shifu)
- AND
- count(*) = (select count(*) from t3 where s2.shifu=shifu) )sc );
上述SQl求出了与师傅“00004”具有相同徒弟群的师傅们,结果为“00009”,只有一个师傅。