腾讯2013校园招聘技术类笔试题
发布于 2014-10-08 12:58:58 | 948 次阅读 | 评论: 0 | 来源: 网友投递
腾讯
腾讯控股有限公司(腾迅)是一家民营IT企业,成立于1998年11月29日,总部位于中国广东深圳,是中国最大的互联网综合服务提供商之一,也是中国服务用户最多,最广的互联网企业之一。
一、选择题
1、数据库表设计最合理的是
A.学生{id,name,age} ,学科{id,name} 分数{学生id,学科id,分数}
B.学生{id,name,age} ,分数{学生id,学科名称,分数}
C.分数{学生姓名,学科名称,分数}
D.学科{id,name},分数{学生姓名,学科id,分数}
解析:C,D肯定不对,B中将学科独立成一个表结构会更加清晰,一个实体对应一张表。
2、在数据库系统中,产生不一致的根本原因是
A.数据存储量太大 B.没有严格保护数据 C.未对数据进行完整性控制 D.数据冗余
解析:基本概念
3、15L和27L两个杯子可以精确地装()L水?
A. 53 B. 25 C. 33 D. 52
解析:设A杯15L,B杯27L,用A打两次水,将B装满,最后A还剩3L,将3L水装至B,还是用A打两次水,将B装满,最后A中有6L,6+27=33.9,12,15..同理
4、考虑左递归文法 S->Aa|b、 A ->Ac | Sd |e,消除左递归后应该为(A)
A. B. C . D.
S->Aa|b S->Ab|a S->Aa|b S->Aa|b
A->bdA'|A' A->bdA'|A' A->cdA'|A' A->bdA'|A'
A->cA'|adA'|ε A->cA'|adA'|ε A->bA'|adA'|ε A->caA'|dA'|ε
解析:e为空集,消除左递归,即消除 有A->A*的情况,消除做递归的一般形式为
U = Ux1 | U x2 |y1|y2
U = y1U' |y2 U'
U' = x1U'|x2U'|e
A = Ac|Aad|bd|e
A =bdA'|A'
A'= cA'|adA'|e
5、下列排序算法中,初始数据集合对排序性能无影响的是()
A.插入排序 B.堆排序 C.冒泡排序 D.快速排序
解析:插入和冒泡再原数据有序的情况下会出现性能的极端情况(O(n),O(n^2)).快速排序在对一个基本有序或已排序的数组做反向排序时,每次patition的操作,大部分元素都跑到了一遍,时间复杂度会退化到O(n^2)。
6、二分查找在一个有序序列中的时间复杂度为()
A.O(N) B.O(logN) C.O(N*N) D.O(N*logN)
7、路由器工作在网络模型中的哪一层()?
A.数据链路层 B.物理层 C.网络层 D.应用层
解析:相关物理硬件和OSI协议层次的对应关系:
物理层 光纤、同轴电缆 双绞线 中继器和集线器
数据链路层 网桥、交换机、网卡
网络层 路由器
传输层 网关
8、对于满足SQL92标准的SQL语句:select foo,count(foo) from pokes where foo>10 group by foo having count(*)>5 order by foo,其执行顺序应该是()
A.FROM ->WHERE -> GROUP BY -> HAVING -> SELECT ->ORDER BY
B.FROM ->GROUP BY ->WHERE -> HAVING -> SELECT ->ORDER BY
C.FROM ->WHERE -> GROUP BY -> HAVING ->ORDER -> BYSELECT
D.FROM ->WHERE ->ORDER BY -> GROUP BY -> HAVING -> SELECT
解析:SQL Select语句完整的执行顺序:
1)from子句组装来自不同数据源的数据;
2)where子句基于指定的条件对记录行进行筛选;
3)group by子句将数据划分为多个分组;
4)使用聚集函数进行计算;
5)使用having子句筛选分组;
6)计算所有的表达式;
7)使用order by对结果集进行排序。
只有select选出了相应的表 才能对其排序,删除之类的操作,因此 合理的答案应该为 from --where-- group by-- having --select-- order by
9.使用深度优先算法遍历下面的图,遍历的顺序为()
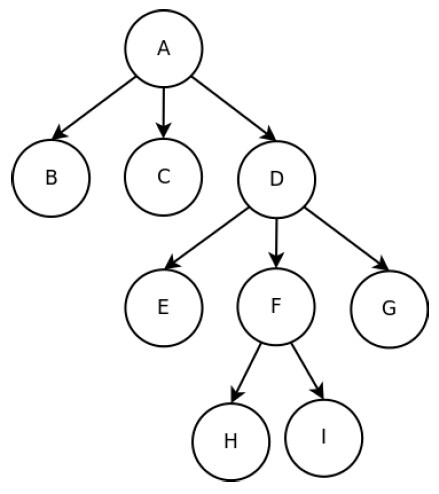
A.ABCDEFGHI B.BCEHIFGDA C.ABCEFHIGD D.HIFEGBCDA
无答案
解析:
用邻接表的方式来表示图
A->B->C->D
B->
C->
D->E->F->G
E->
F->H->I
G->
H->
I->
图的深度优先搜索是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节 点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所 有节点都被访问为止。
所以正确的过程是 A->B->C->D->E->F->H->I->G
10.UNIX系统中,目录结构采用
A.单级目录结构 B.二级目录结构 C.单纯树形目录结构 D.带链接树形目录结构
11.请问下面的程序一共输出多少个“-”?
- #include <stdio.h>
- #include <sys/types.h>
- #include <unistd.h>
- int main(void)
- {
- int i;
- for(i=0; i<2; i++)
- {
- fork(); //复制父进程,调用一次,返回两次
- printf("-"); //缓冲区数据
- }
- return 0;
- }
A.2个 B .4个 C.6个 D.8个
解析:
关键1.fock之后的代码父进程和子进程都会运行;
关键2.printf(“-”);语句有buffer,所以,对于上述程序,printf(“-”);把“-”放到了缓存中,并没有真正的输出,在fork的时候,缓存被复制到了子进程空间,所以,就多了两个,就成了8个,而不是6个。
12.请问下面的程序一共输出多少个“-”?
- #include <stdio.h>
- #include <sys/types.h>
- #include <unistd.h>
- int main(void)
- {
- int i;
- for(i=0; i<2; i++)
- {
- fork(); //复制父进程,调用一次,返回两次
- printf("-\n"); //缓冲区数据
- }
- return 0;
- }
A.2个 B .4个 C.6个 D.8个
解析:printf("-\n")刷新了缓冲区
13.避免死锁的一个著名的算法是()
A.先入现出法 B.银行家算法 C.优先级算法 D.资源按需分配法
14.怎么理解分配延迟(dispatch lantency)
A.分配器停止一个进程到开启另一个进程的时间 B. 处理器将一个文件写入磁盘的时间
C. 所有处理器占用的时间 D.以上都不对
解析:分派程式停止某一个处理元使用中央处理器,并分派中央处理器给另一个处理元所需的时间,称为分派时间(Dispatch Latency)。
15.以下哪一个不是进程的基本状态?
A. 阻塞态 B.执行态 C.就绪态 D. 完成态
解析:进程状态转移图
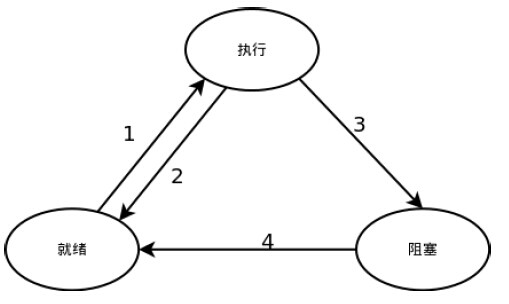
1:就绪->执行, 当前运行进程阻塞,调度程序选一个优先权最高的进程占有处理机;
2:执行->就绪, 当前运行进程时间片用完;
3:执行->阻塞,当前运行进程等待键盘输入,进入了睡眠状态。
4:阻塞->就绪,I/O操作完成,被中断处理程序唤醒。
16.假定我们有3个程序,每个程序花费80%的时间进行I/O,20%的时间使用CPU。每个程序启动时间和其需要使用进行计算的分钟数如下,不考虑进程切换时间。
程序编号 启动时间 需要CPU时间(分钟)
1 00:00 3.5
2 00:10 2
3 00:15 1.5
请问在多线程/进程环境下,系统的总响应时间是()
A.22.5 B.23.5 C.24.5 D.25.5
解答:多道编程时CPU利用率的求法:
只有一个进程的时候,CPU利用率肯定是20%。
两个进程的时候:CPu利用率是:20% + (1-20%)*20% = 36%
三个进程是:36% + (1-36%)*20% = 48.8%
其它的依次类推。
0-10分钟的时候,只有一个进程1在运行。
单进程CPU占有率是20%,所以这10分钟内,进程1消耗了2分钟的CPU。进程2是0,进程3也是0
然后在10-15分钟内,有两个进程在运行(1和2),双进程的CPU利用率是36%,
所以,这五分钟内,CPU一共利用了1.8分钟,平均分给每个进程,是0.9分钟。
此时,进程1已经占用了CPU 2.9分钟,还需要0.6分钟,这时候有三个进程在运行,所有总的CPU时间需要1.8分钟。
三进程的CPU利用率是48.8%,所以总共需要1.8/0.488=3.69分钟。这时,进程1已经3.5分钟的CPu利用时间利用完了。
此时还剩下2和3号进程在运行。
2号进程还需要0.5分钟,所以0.5×2/0.36=2.78,此时2号进程的2分钟CPU时间也利用完了。
3号进程还需要0.4分钟的CPU利用时间。0.4/0.2 = 2
17.在所有非抢占CPU调度算法中,系统平均响应时间最优的是()
A.实时调度算法 B.短任务优先算法 C.时间片轮转算法 D.先来先服务算法
18.什么是内存抖动(Thrashing)?
A.非常频繁的换页活动 B.非常高的CPU执行活动 C.一个极长的执行进程 D.一个极大的虚拟内存交换活动
解析:页面的频繁更换,导致整个系统效率急剧下降,这个现象称为内存抖动。
抖动一般是内存分配算法不好,内存太小引或者程序的算法不佳引起的页面频繁从内存调入调。
19. Belay's Anomaly 出现在哪里()
A.内存管理算法 B.内存换页算法 C.预防死锁算法 D.磁盘调度算法
解析:Belady异常(Belady Anomaly):有些情况下,页故障率(缺页率)可能会随着所分配的帧数的增加而增加。
原因:因为使用了不恰当的演算法(如FIFO),虽然空间够多(frame够多),但因为总是选到不应该被swap的page,所以反而让page fault次数变多了。
20.下面的生产者消费者程序中,哪个不会出现死锁,并且开销最少?
解析:代码太多,不做 - -
二、填空题
21.将下图进行拓扑排序后,对应的序列为 ABCFD
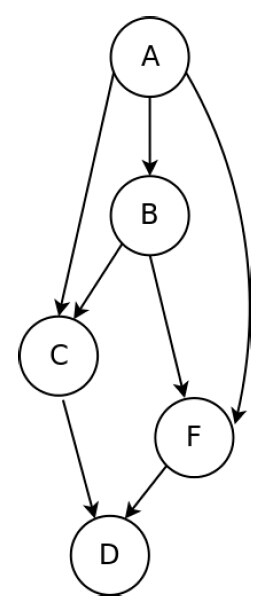
解析:拓扑排序的定义:对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若<u,v> ∈E(G),则u在线性序列中出现在v之前。
22.下面的函数使用二分查找算法,对已按升序排序的数组返回所要查找的数值的数据位置,请填写缺少的两句语句:
- int* BinarySearch(int* arrayAddress, int arrayLength, int valueToSearch)
- {
- int head = 0 ;
- int tail = arrayLength - 1;
- while(head < tail)
- {
- mid = (head + tail)/2;
- if(arrayAddress[mid] > valueToSeatcj)
- tail = mid - 1;
- else
- head = mid + 1;
- }
- if(tail < arrayLength && arrayAddress[tail] == valueToSearch)
- return &arrayAddress[tail];
- else
- return NULL;
- }
tail = mid -1 ;
head = mid + 1;
23.一个有N个正数元素的一维数组(A[0], A[1], A[2]...,A[N-1]), 求连续子数组和的最大值。
- int max(int a,int b)
- int MaxSum(int *A, int length)
- {
- int nStart = A[0];
- int nAll = A[0];
- for(int i=1; i<lenght; i++)
- {
- nStart = max(nAll + A[i], 0);
- nAll = max(nAll, nStart);
- }
- return nAll;
- }
nStart = max(nAll + A[i] , 0);
nAll = max(nAll, nStart);
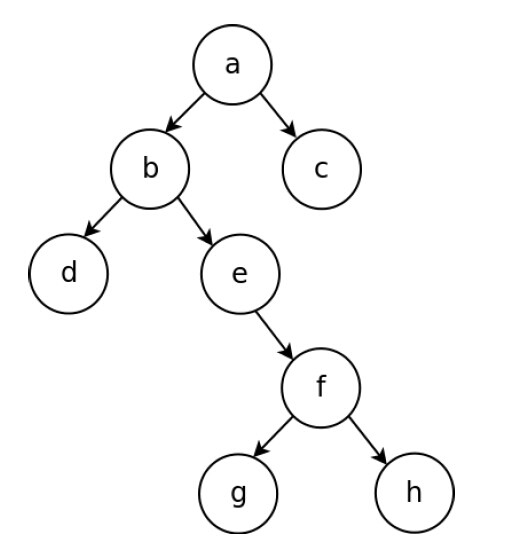
24. 请给出二叉树的前序遍历 abdefghc
25.最长递增子序列(LIS)表示在一个序列中,保持递增的最长子序列,比如(2,1,4,2,3,7,4,6)的LIS是{1,2,3,4,6},则LIS的长度是5.
对于一个有N个元素的序列,得到LIS的长度的最优时间复杂度是 O(nlogn) ,空间复杂度是o(n) 。
26.给一系列的数1,2,3,,,n(有序的)和一个栈(stack),这个栈无限大,将这n个数按照顺序放入栈中,但是随机的从栈中弹出,n=5,一共有多少中弹栈方式。42
解析:这是卡特兰数的典型应用。Catalan数的定义令h(1)=1,Catalan数满足递归式:h(n) = h(1)*h(n-1) + h(2)*h(n-2) + ... + h(n-1)h(1),n>=2该递推关系的解为:h(n) = C(2n,n)/(n+1),n=1,2,3,...(其中C(2n,n)表示2n个中取n个的组合数)
h(5) = C(10,5)/6 = 42
27.请给出表达式 a + b*(c-d)/e-f 的逆波兰式。abcd-*e/+f-
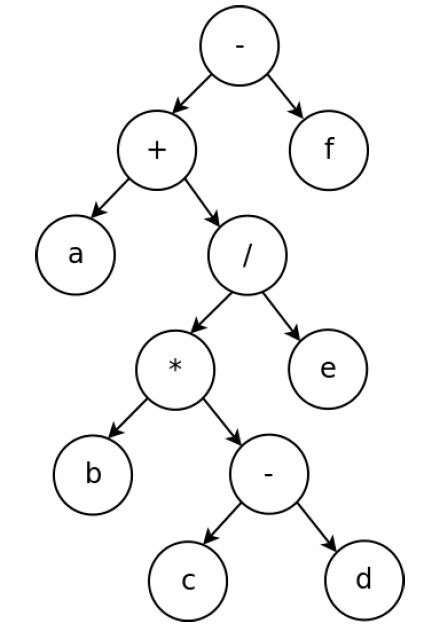
解析:先画出式子的二叉树,再写出后序遍历的结果。